
2023 so far has been a year unlike any in the recent past. Machine learning (ML), specifically generative AI and the possibilities that it enables, has taken many industries by storm and developers and data practitioners are exploring ways to bring the benefits of gen AI to their users. At the same time, most businesses are going through a period of consolidation in the post-COVID era and are looking to do more with less. Given that backdrop, it is not surprising that more and more data leaders are seizing the opportunity to transform their business by leveraging the power for streaming data to drive productivity and save costs.
To enable and support you in that journey, the Dataflow team here at Google has been heads down working on a number of product capabilities. Considering that many of you are likely drawing your plans for the rest of the year and beyond, we want to take a moment to give you an overview of Dataflow’s key new capabilities.
Autotuning
Autotuning is at the foundation of Dataflow. It is one the key reasons why users choose it. Operating large-scale distributed systems is challenging, particularly if that system is handling data in motion. That is why autotuning has been a key focus for us. We’ve implemented the following autotuning features:
- Asymmetric autoscaling to improve performance by independently scaling user workers and backend resources. For example, a shuffle-heavy job with asymmetric autoscaling benefits from fewer user workers, less frequent latency spikes and more stable autoscaling decisions. This feature is GA.
- In-flight job option updates to allow customers to update autoscaling parameters (min/max number of workers) for long-running streaming jobs without downtime. This is helpful for customers who may want to save costs during when there are spikes in latency or adjust downscaling limits in anticipation of a traffic spike to ensure low latency, and can’t tolerate the downtime and latency associated with a running pipeline update. This feature is GA.
- Fast worker handover: Typically, during autoscaling, new workers have to load pipeline state from the persistent store. This is a relatively slow operation and results in increased backlogs, increasing latency. To address this, Dataflow now transfers state directly from workers, reducing latency.
- Intelligent autoscaling that takes into account key parallelism (aka key-based throttling) to improve utilization and a number of other advanced auto tuning techniques.
- Intelligent downscale dampening: One of the common challenges with streaming pipelines is that aggressive downscaling causes subsequent upscaling (yo-yoing). To address this problem, Dataflow now tracks scaling frequencies and intelligently slows downscaling when yo-yoing is detected.
- Autosharding for BigQuery Storage Write API: Autosharding dynamically adjusts the number of shards for BigQuery writes so that the throughput keeps up with the input rate. Previously, autosharding was only available for BigQuery Streaming Inserts. With this launch, the BigQuery Storage API also has an autosharding option. It uses throughput and backlog to determine the optimal number of shards per table, reducing resource waste.
Performance and efficiency
Every user that we talk to wants to do more with less. The following efficiency- and performance-focused features help you maximize the value you get from underlying resources.
In Dataflow environments, CPU resources are often not fully utilized. Tuning the number of threads can increase utilization. But hand-tuning is error-prone and leads to a lot of operational toil. Staying true to our serverless and no-ops vision, we built a system that automatically and dynamically adjusts the number of threads to deliver better efficiency. We recently launched this for batch jobs; support for streaming will follow.
Vertical autoscalingfor batch jobs
Earlier this year we launched vertical autoscaling for batch jobs. Vertical autoscaling reduces operational toil for developers rightsizing their infrastructure. Vertical autoscaling works hand in hand with horizontal autoscaling to automatically adjust the amount of resources (specifically memory) to prevent job failures because of out of memory errors.
ARM processors in Dataflow
We’ve added support for T2A VMs in Dataflow. Powered by Ampere® Altra® Arm-based processors, T2A VMs deliver exceptional single-threaded performance. We plan to expand ARM support in Dataflow further in the future.
SDK (Apache Beam) performance improvements
Over the course of this year we made a number of enhancements to Apache Beam that has resulted in substantial performance improvements. These include:
- More efficient grouping keys in the pre-combiner table
- Improved performance for TextSource by reducing how many byte[]s are copied
- Grouping table now includes sample window size
- No more wrapping lightweight functions with Contextful.
- An optimized PGBK table
- Optimization to use a cached output receiver
Machine learning
Machine learning relies on have good data and the ability to process that data. Many of you use Dataflow today to process data, extract features, validate models and make predictions. For example, Spotify uses Dataflow for large-scale generation of ML podcast previews. In particular, generating real-time insights with ML is one of the most promising ways of driving new user and business value, and we continue to focus on making ML easier and simpler out of the box with Dataflow. To that end, earlier this year we launched RunInference, a Beam transform for doing ML predictions. It replaces complex, error-prone, and often repetitive code with a simple built-in transform. RunInference lets you focus on your pipeline code and abstracts away the complexity of using a model, allowing the service to optimize the backend for your data applications. We are now adding a number of new features and enhancements to RunInference.
Dataflow ML RunInference now has the ability to update ML models (Automatic Model Refresh) without stopping your Dataflow streaming jobs. This now means updating your production pipelines with the latest and greatest models your data science teams are producing is easier. We have also added support for:
- Dead-letter queue – Ensures bad data does not cause operational issues, by allowing you to easily move them to a safe location to be dealt with out of the production path.
- Pre/post–processing operations – Lets you encapsulate the typical mapping functions that are done on data before a call to the model within one RunInference transform. This removes the potential for training or serving skew.
- Support for remote inference with Vertex AI endpoints in VertexAIModelHandler.
Many ML cases benefit from GPU both in terms of cost effectiveness as well as performance benefits for tasks such as ML predictions. We have launched a number of enhancements to GPU support including multi-process service (MPS), a feature that improves efficiency and utilization of GPU resources.
Choice is of course always a key factor and this true for GPUs, especially when you want to match the right GPU for your specific performance/efficiency needs. To this end we are also adding support for NVIDIA A100 80 Gig and the NVIDIA L4 GPU, which is rolling out this quarter.
Developer experience
Building and operating streaming pipelines is different from batch pipelines. Users need the right tooling to build and operate pipelines that can run 24*7 and offer high SLAs to downstream customers. The following new capabilities are designed with developers and data engineers in mind:
- Data sampling – One common challenge that users have is the following knowing that there is a problem, but having no way of associating the problem with a particular set of data that was processed when the problem occurred. Data sampling is designed to address this specific problem. Data sampling lets you observe actual data at each step of a pipeline, so you can debug problems with your pipeline.
- Straggler detection – Stragglers are work items that take significantly longer to complete than other work items in the same stage. They reduce parallelism and block new work from starting. Dataflow can now detect stragglers and can also try to determine the cause of the straggler. You can view detected stragglers right in the UI, viewing them by stage or worker, for more flexibility
- Cost monitoring – Dataflow users have asked for the ability to easily look up estimated costs for their jobs. Billing data, including billing exports, is a reliable and authoritative source for billing data. Now, to support easy lookup of billing estimates for individual users who may not have billing data access, we have built cost estimation right into the Dataflow UI.
- Autoscaling observability – Understanding how autoscaling impacts a job is one frequently requested feature. You can now view autoscaling monitoring charts for streaming jobs within the Dataflow monitoring interface. These charts display metrics over the duration of a pipeline job and include information such as the number of worker instances used by your job at any point in time, autoscaling logs, estimated backlog over time, and average CPU utilization over time.
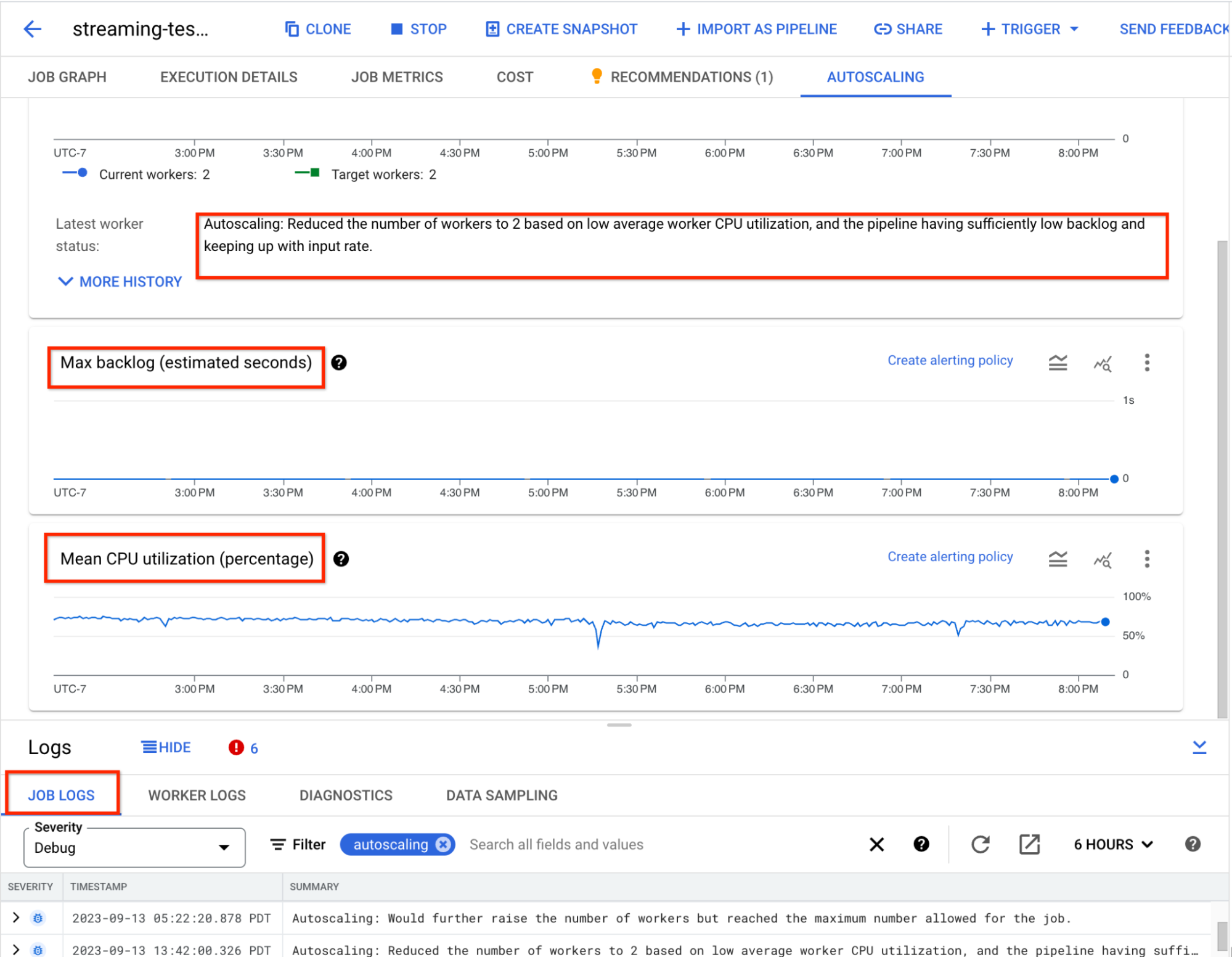
- Job lifecycle Management – Thanks to Eventarc integration, you can now create event-driven workflows triggered by state changes in your Dataflow jobs.
- Regional placement for workers allow your jobs to automatically utilize all available zones within the region so that your jobs are not impacted by resource obtainability issues.
- UDF builder for templates – Many Dataflow users rely on Dataflow templates, either provided by Google or built by your organization for repetitive tasks and pipelines that can be easily templatized. One of the powerful features of templates is the ability to customize processing by providing an UDF. We have now made the experience even easier by allowing you to create and edit UDFs right in the UI. You continue to have the ability to use a previously created UDF. In addition we have published UDF samples in GitHub that cover many common cases.
- Cloud Code plug-in for Dataflow – Cloud Code makes it easier to create, deploy and integrate applications in Google Cloud using your favorite IDEs such as IntelliJ. The Dataflow plug-in allows you to execute and debug Dataflow pipelines from the IntelliJ IDE directly.
Ecosystem integration
None of these new capabilities are useful if you can’t get to the data that you need. That’s why we continue to expand the products and services Dataflow works. For instance:
- You can now implement streaming analytics on analytics data with the new Google Ads to BigQuery Dataflow template. It gives users the power to incorporate minutes-old, fine-grained data into your marketing strategy.
- New MySQL to BigQuery, PostgreSQL to BigQuery, SQL Server to BigQuery, and BigQuery to Bigtable templates connect your operational and analytical systems and Templates for Splunk, Datadog, Redis and AstraDB integrate data from and into other commonly used SaaS products.
Industry solutions
To reduce the time it takes for you to architect and deploy solutions for your business problems, we partnered with Google’s Industry Solutions team to launch Manufacturing Data Engine, an end-to-end solution that uses Dataflow and other Google Cloud services to enable “connected factory” use cases from data acquisition to ingestion, transformation, contextualization, storage and use case integration, thereby accelerating time to value and enabling faster ROI. We plan to launch more solutions like Manufacturing Data Engine.
Learning and development
It’s easy to get started with Dataflow. Templates provide a turn-key mechanism to deploy pipelines, and Apache Beam is intuitive enough to write production-grade pipelines in a matter of hours. At the same time, you get more benefit out of the platform if you have a deep understanding of the SDK and the benefit of best practices. Here are some new developer learning and development assets:
- Dataflow Cookbook: This comprehensive collection of code samples will help you learn, develop and solve sophisticated problems.
- We partnered with the Apache Beam community to launch Tour of Beam (an online, always-on, no-setup notebook environment that allow developers to interactively learn Beam code), Beam Playground (a free online tool to interactively try out Apache Beam examples and transforms), and Beam Starter Projects (easy-to-clone starter projects for all major Apache Beam languages to make getting started easier). Beam Quest certification complements these learning and development efforts, providing users recognition that will help them build accreditation,
- We hosted the Beam Summit in our New York Pier 53 campus on June 13-15. All of the content (30 sessions spread out across 2 days and 6 workshops) from the Beam Summit is now available online.
- Lastly, we are working with the Apache Beam community to host the annual Beam College. This virtual event will help developers with various levels of Beam expertise to learn and master new concepts with lectures, hands-on workshops, and expert Q&A sessions. Register here for the October 23-27 event.
Thanks for reading this far. We are excited to get these capabilities to you and looking forward to seeing all the ways in which you use the product to solve your hardest challenges.