
When your data is siloed data across lakes and warehouses, it can be hard to transform outcomes with your data. Apache Iceberg is an open table format that provides data management capabilities for data hosted on object stores and enables organizations to run analytics and AI use cases over a single copy of data. A growing community of data engineers, customers, and industry partners are contributing, integrating, and deploying Iceberg, making it the standard for organizations building open-format lakehouses.
To help customers on this journey, we announced support for Iceberg through BigLake in October, 2022. Since its preview, many customers have started building lakehouse workloads using Apache Iceberg as their data management layer, and this support is now generally available.
Unify analytics, streaming and AI use cases over a single copy of data
You can use open-source engines to process and ingest data into Iceberg tables, and BigQuery can query those tables. Since the preview, customers have also used Spark, Trino and Flink to process Iceberg tables and make those tables available to their BigQuery users. Then, BigLake Metastore provides shared metadata for Iceberg tables across BigQuery and open-source engines, eliminating the need to maintain multiple table definitions. Further, you can provide BigQuery datasets and table properties when creating new Iceberg tables in Spark, and those tables become automatically available for the BigQuery user to query.
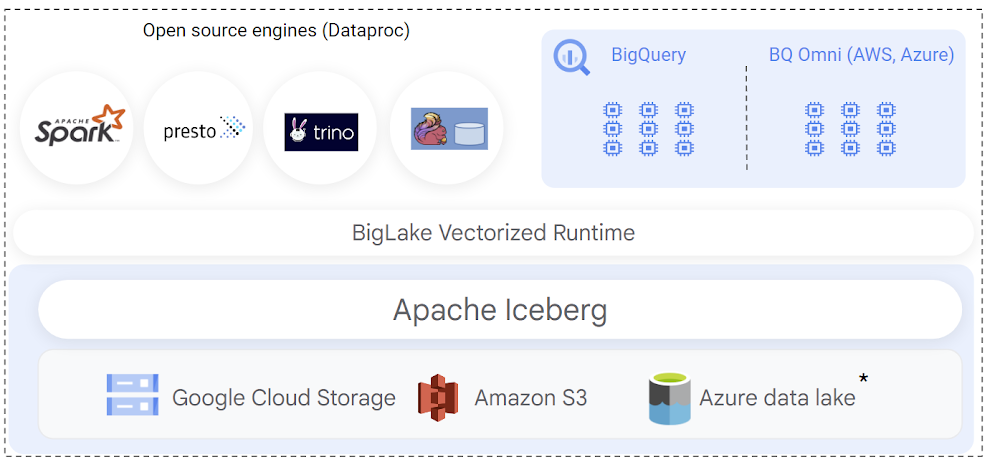
When implementing Iceberg lakehouse workloads, query performance is a top priority for data warehouse users. BigQuery natively integrates with the Iceberg transaction logs and leverages its rich metadata for efficient query planning. Query plans are designed to reduce BigQuery compute consumption by lowering the amount of scanned data, by optimizing joins, and by improving data-plane parallelism. The net result is that you get better query performance and lower slot usage when querying BigLake Iceberg tables.
This GA release also adds support to provide automatic synchronization of table schema in BigQuery when the table is modified through an open-source engine.
Engine-agnostic, industry-leading security and governance built-in
Customers have been telling us that building Iceberg lakehouses in a secure and governed manner is a top priority. BigLake support for Iceberg provides fine-grained access control, including row- and column-level security as well as data masking to simplify this. These features are designed to work independently of the query engine. During the preview, we expanded BigQuery to also support differential privacy for all tables including Iceberg.
You can also define security policies on a BigLake Iceberg table using BigQuery. Security policies are then enforced regardless of the query engine used — BigQuery natively enforces these policies at runtime, and open-source engines can securely access the data using the BigQuery Storage API. The BigQuery Storage API enforces the security policies at the data-plane layer, and is offered via pre-built connectors for Spark, Trino, Presto and TensorFlow. You can also use client libraries to build connectors for custom applications.
New use cases with multi-cloud Iceberg lakehouse
The open nature of Apache Iceberg lets you build multi-cloud lakehouses with uniform management of data. With this launch, you can now create BigLake Iceberg tables on Amazon S3, and query them using BigQuery Omni. BigLake’s performance and fine-grained access control features seamlessly extend to multi-cloud Iceberg tables, so you can securely perform cross-cloud analytics with BigQuery. We’ll extend similar support to Azure data lake Gen 2 in the coming weeks.
Apache Iceberg’s format uniformity across clouds also enables new data sharing use cases to help you share data with your customers, partners and suppliers, regardless of which cloud they are using. BigLake Iceberg tables on Cloud Storage or on Amazon S3 can be shared through Analytics Hub and consumed via BigQuery or OSS engines via BigQuery Storage Read API, providing an open sharing standard and the flexibility to use multiple query engines. A notable example of this is the recently announced Salesforce Data Cloud data sharing use case, which enables bi-directional cross-cloud data sharing between Salesforce and BigQuery and which is powered by Iceberg.
Getting started
To create and query your first Iceberg table, following the documentation. or run a quick proof of concept on our analytics lakehouse with the Iceberg jump start solution.