
Ever wanted to move your data from Pub/Sub into Cloud Storage? Until today, data engineers focused on building the data lake for their organizations had to put together complex data pipelines to ingest streaming data from Pub/Sub into Cloud Storage. In order to land streaming data into Cloud Storage, they either needed to write their own custom Cloud Storage subscriber, or to leverage intermediate Dataflow jobs. Writing a custom Cloud Storage subscriber comes with time-consuming design, development and maintenance of the subscriber code. Dataflow pipelines (including ones built with Dataflow templates) can be helpful, but they can be more heavyweight than necessary for simply streaming data from Pub/Sub into Cloud Storage.
Now, you no longer need to build complex pipelines to ingest your streaming data into Cloud Storage. The Pub/Sub team is excited to announce Cloud Storage subscriptions, a new type of subscription to help you write your raw data into Cloud Storage without any transformations in between.
Pub/Sub Cloud Storage subscriptions offer multiple benefits:
-
Simplified data pipelines – Streamline the ingestion pipelines for your data lake by using Cloud Storage subscriptions, which removes the need for an intermediate process (i.e., a custom subscriber or Dataflow). Cloud Storage subscriptions are fully managed by Pub/Sub, thus reducing the additional maintenance and monitoring overhead that comes with intermediate processes.
-
Lower latency and costs – Cloud Storage subscriptions remove the additional costs and latency introduced by Dataflow or a custom subscriber. (If Pub/Sub data needs to be transformed before landing into Cloud Storage, we still recommend leveraging Dataflow.)
-
Increased flexibility – Cloud Storage file batching options provide flexibility on how to batch messages and then land that data in Cloud Storage.
Effortless streaming data ingestion
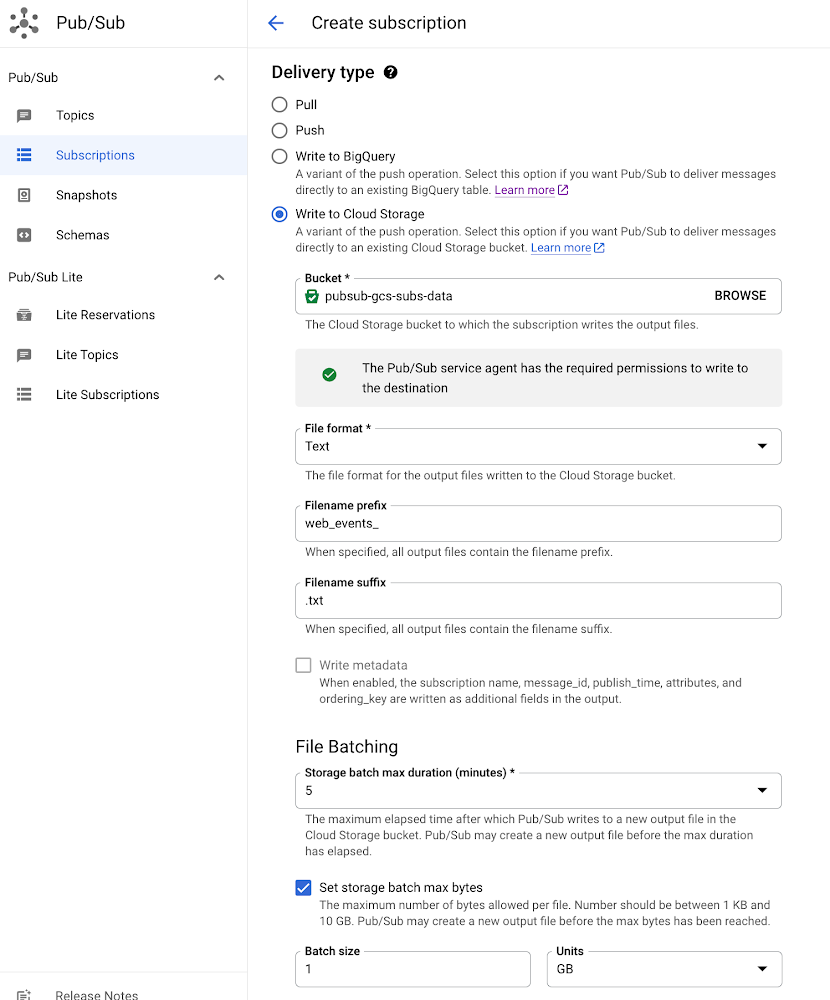
Using Cloud Storage subscriptions is very easy. To create a Cloud Storage subscription, simply specify a Cloud Storage bucket name where you would like Pub/Sub to write files. You can also specify additional subscription properties:
- File batching – This option allows you to decide when you want to create a new output file in the provided Cloud Storage bucket. A new output file is created in the provided Cloud Storage bucket when the specified value in one of the following options is exceeded.
-
Maximum duration in minutes (required)
-
Maximum bytes in KBs or GBs (optional)
Please refer to the documentation for more information on batching setting limits and defaults.
-
File format – While creating a Cloud Storage subscription, you can select one of the following file formats:
-
Text – Store messages as plain text
-
Avro – Store messages in Apache Avro binary format. You can also select the “write metadata” option with the Avro format, allowing you to store the message metadata (message_id, publish_time etc.) along with the message.
-
File prefix and suffix – You can also specify file prefix and suffix that will used to create file names with the following format:
<file-prefix><UTC-date-time>_<uuid><file-suffix>, where <uuid> is an auto-generated unique string for the file. Using custom file prefixes and suffixes can be helpful for downstream processing, when you want to process a specific set of files.
With Cloud Storage subscriptions, Pub/Sub is making it really easy and seamless to ingest your streaming data into your Cloud Storage data lakes, accelerating your time to insights and streamlining your data ingestion pipelines.
To get started, read more about Pub/Sub Cloud Storage subscriptions, or simply create a new Cloud Storage subscription for a topic using the Google Cloud console, Google Cloud CLI (gcloud), the Google Cloud client library, or the Pub/Sub API.