
Revised version for your consideration
Data engineers know that eventing is all about speed, scale, and efficiency. Event streams — high-volume data feeds coming off of things such as devices such as point-of-sale systems or websites logging stateless clickstream activity — process lightweight event payloads that often lack the information to make each event actionable on its own. It is up to the consumers of the event stream to transform and enrich the events, followed by further processing as required for their particular use case.
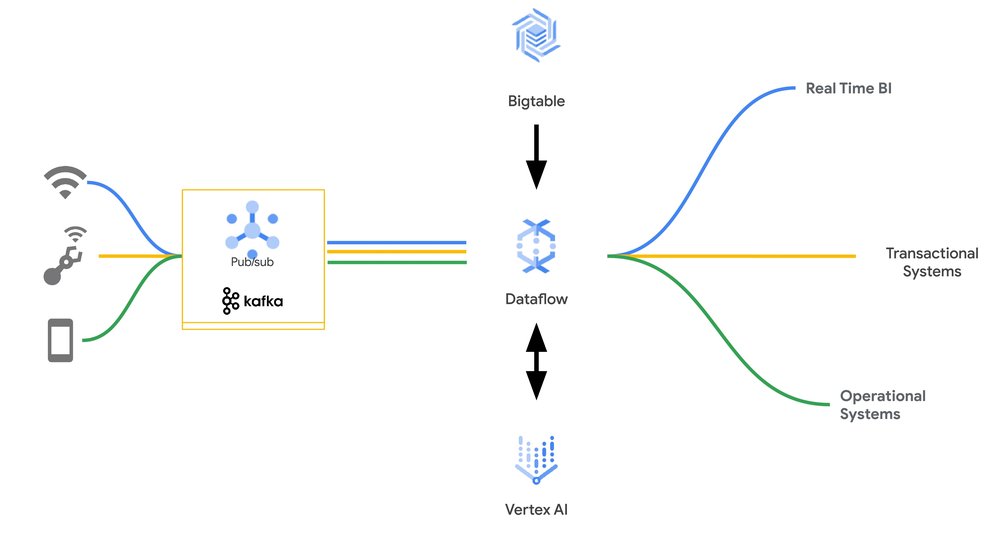
Key-value stores such as Bigtable are the preferred choice for such workloads, with their ability to process hundreds of thousands of events per second at very low latencies. However, key value lookups often require a lot of careful productionisation and scaling code to ensure the processing can happen with low latency and good operational performance.
With the new Apache Beam Enrichment transform, this process is now just a few lines of code, allowing you to process events that are in messaging systems like Pub/Sub or Apache Kafka, and enrich them with data in Bigtable, before being sent along for further processing.
This is critical for streaming applications, as streaming joins enrich the data to give meaning to the streaming event. For example, knowing the contents of a user’s shopping cart, or whether they browsed similar items before, can bring valuable context to clickstream data that feeds into a recommendation model. Identifying a fraudulent in-store credit card transaction requires much more information than what’s in the current transaction, for example, the location of the prior purchase, count of recent transactions or whether a travel notice is in place. Similarly, enriching telemetry data from factory floor hardware with historical signals from the same device or overall fleet statistics can help a machine learning (ML) model predict failures before they happen.
The Apache Beam enrichment transform can take care of the client-side throttling to rate-limit the number of requests being sent to the Bigtable instance when necessary. It retries the requests with a configurable retry strategy, which by default is exponential backoff. If coupled with auto-scaling, this allows Bigtable and Dataflow to scale up and down in tandem and automatically reach an equilibrium. Beam 2.5.4.0 supports exponential backoff, which can be disabled or replaced with a custom implementation.
Lets see this in action:
- code_block
- <ListValue: [StructValue([('code', 'with beam.Pipeline() as p:rn output = (prn | "Read from PubSub" >> beam.io.ReadFromPubSub(subscription=SUBSCRIPTION)rn | "Convert bytes to Row" >> beam.ParDo(DecodeBytes())rn | "Enrichment" >> Enrichment(bigtable_handler)rn | "Run Inference" >> RunInference(model_handler)rn )'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e72b34f7fd0>)])]>
The above code runs a Dataflow job that reads from a Pub/Sub subscription and performs data enrichment by doing a key-value lookup with Bigtable cluster. The enriched data is then fed to the machine learning model for RunInference.
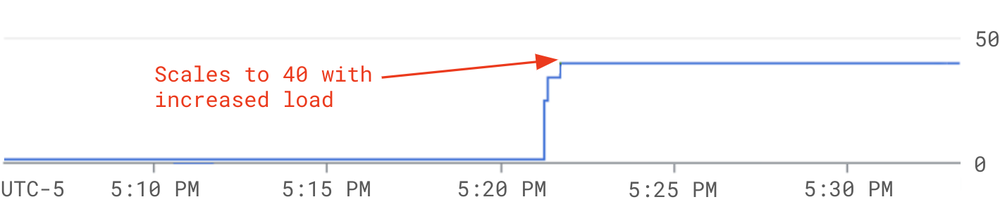
The pictures below illustrate how Dataflow and Bigtable work in harmony to scale correctly based on the load. When the job starts, the Dataflow runner starts with one worker while the Bigtable cluster has three nodes and autoscaling enabled for Dataflow and Bigtable. We observe a spike in the input load for Dataflow at around 5:21 PM that leads it to scale to 40 workers.
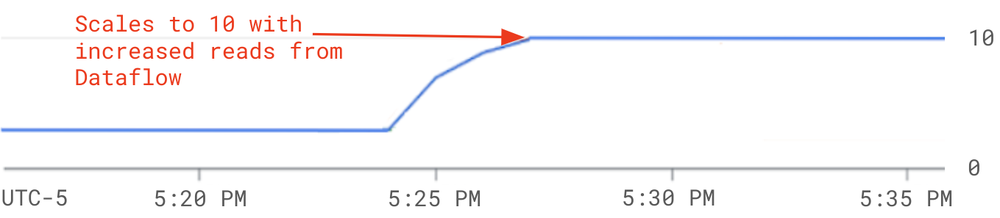
This increases the number of reads to the Bigtable cluster. Bigtable automatically responds to the increased read traffic by scaling to 10 nodes to maintain the user-defined CPU utilization target.
The events can then be used for inference, with either embedded models in the Dataflow worker or with Vertex AI.
This Apache Beam transform can also be useful for applications that serve mixed batch and real-time workloads from the same Bigtable database, for example multi-tenant SaaS products and interdepartmental line of business applications. These workloads often take advantage of built-in Bigtable mechanisms to minimize the impact of different workloads on one another. Latency-sensitive requests can be run at high priority on a cluster that is simultaneously serving large batch requests with low priority and throttling requests, while also automatically scaling the cluster up or down depending on demand. These capabilities come in handy when using Dataflow with Bigtable, whether it’s to bulk-ingest large amounts of data over many hours, or process streams in real-time.
Conclusion
With a few lines of code, we are able to build a production pipeline that translates to many thousands of lines of production code under the covers, allowing Pub/Sub, Dataflow, and Bigtable to seamlessly scale the system to meet your business needs! And as machine learning models evolve over time, it will be even more advantageous to use a NoSQL database like Bigtable which offers a flexible schema. With the upcoming Beam 2.55.0, the enrichment transform will also have caching support for Redis that you can configure for your specific cache. To get started, visit the documentation page.