
Yahoo is constantly seeking ways to optimize the efficiency of streaming large-scale data processing pipelines. In a recent project, Google Cloud and Yahoo focused on benchmarking the cost and performance for two specific use cases on two stack choices: Apache Flink in a self-managed environment, and Google Cloud Dataflow.
In this post, we details our benchmark setup, methodology, the use cases in scope, key findings, and the Dataflow configurations that helped us streamline performance. We hope these learnings will help you find new ways to optimize your own streaming pipelines.
Benchmark setup
We designed our benchmark to ensure a quick, fair and rough comparison on Yahoo typical use cases; we chose two representative workloads — one compute-heavy and the other IO-heavy. The result of this benchmark would indicate which platform to recommend to Yahoo teams for streaming, including writing results to Bigtable, Cloud Storage, and other complex streaming pipelines discussed below.
Test setup infrastructure

For our test setup, we set the configured the following environment:
-
Metric: Our primary focus was compute cost per unit of throughput — the volume of data processed per unit of time. We aimed to understand the costs of running Apache Flink and Dataflow pipelines at a sustained throughput of 20,000 records per second. “Cost” for Flink excludes operational overhead of setting up and running the job in the respective platform (engineering hours used).
-
Workload: We simulated a 10TB data stream from Pub/Sub, creating a backlog of 100+ million records to maintain a constant load.
-
Controlled environment: To focus on the impact of specific configurations, we initially disabled autoscaling by fixing Flink’s resource allocation and setting a limit on Dataflow worker count. This allowed us to compare costs at a consistent throughput, i.e., cost per unit of throughput. For this experiment, we would consider to test autoscaling in terms of ease of operation for managed Flink and Dataflow (operational, resource management cost) if the benchmarking results were not enough. However, because the benchmarking result was more than satisfactory, we did not need to consider the autoscaling management resource.
Use-case details:
As stated above, we evaluated two typical use cases, one compute-heavy, and the other I/O heavy:
- Write Avro to Parquet (I/O-intensive): This use case is a streaming job that reads Avro messages, which then get windowed to certain time frames (1-5 mins), and outputted to Cloud Storage as Parquet.
-
Data enrichment and calculation (compute-heavy): This workload simulates active user analysis and event enrichment. This involved Beam state management, key reshuffling, and making external calls to another service.
Notes:
-
We excluded the operational costs of managing infrastructure for both platforms.
-
If the benchmark had shown similar costs for both Apache Flink and Dataflow infrastructure, we still would have picked Dataflow because it is a managed service. We were ready to benchmark a third use-case if the two use-cases above were not conclusive.
Understanding the results
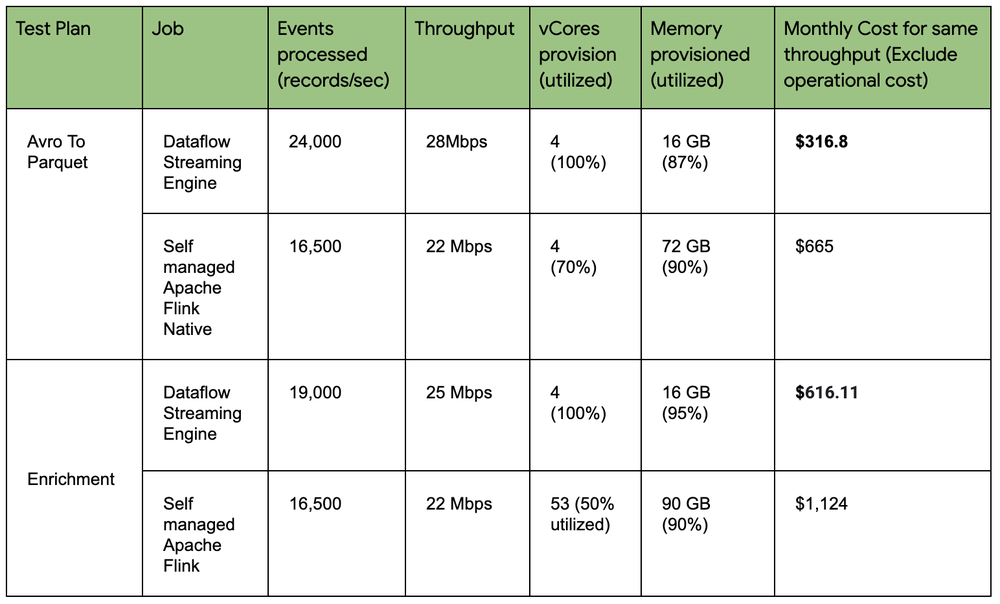
The result shows that Dataflow is around 1.5 – 2 times more cost effective in comparison to self-managed Apache Flink on our test cases. Let’s understand in more detail how we achieved these numbers.
The idea for the benchmark was to calculate Flink/Dataflow costs for achieving similar throughput, with the goal of having the number of messages processed per second for each of the streaming applications to be as close as possible. In the table above, for the Enrichment use case, the number of provisioned vCPUs on GKE is approximately 13x higher compared to Dataflow. This is not because Flink is inefficient, but because in Dataflow, Streaming Engine sends a lot of the heavy computation to the Dataflow backend. Of course, there was some room to improve Flink utilization, but doing that turned out to make the job unstable, so we did not spend further time there and calculated the cost for 32 vCPUs (2 x n2d-standard-16 machines) as if utilization was ~75%.
You can think of the Dataflow backend as a Google Cloud backend resource for doing heavy computation (e.g., shuffling) rather than doing it on Dataflow’s worker. This naturally makes Dataflow require fewer vCPUs, makes it more robust, and provides much more consistent throughput. This is critical for Yahoo use cases to be able to leverage the Streaming Engine.
In the image below, our Dataflow pipeline uses a newly released cost billing feature that calculates cost based on Streaming Engine Processing Unit. From our testing, the new billing feature was able to optimize pipeline costs for our throughput-based workloads. On the Flink side, we installed telemetry and monitored Pub/Sub throughput to check the amount of resources it was using. For the Flink setup, we didn’t spend too much time tuning the job and therefore, assumed lowest cost if we had improved utilization, i.e., the cost was based on having 32 vCores assuming we could get around 75% CPU utilization as a best case.
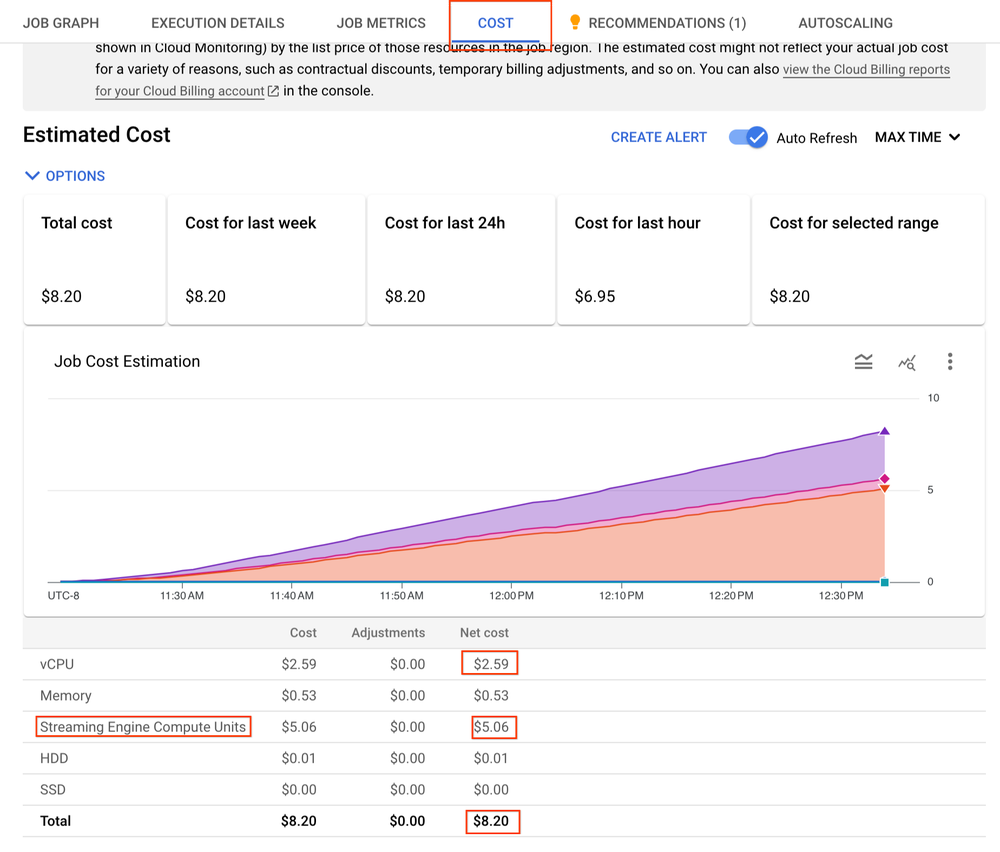
To see a detailed breakdown of the cost of Dataflow, go to the Dataflow Cost tab, like this:
Here is the Dataflow command that we use to deploy our settings (in gradle):
- code_block
- <ListValue: [StructValue([('code', 'task dataflow(type:JavaExec) {rn mainClass = "com.google.benchmark.BenchmarkDataflow"rn classpath = sourceSets.main.runtimeClasspathrnrn args = [rn "–enableStreamingEngine",rn "–workerMachineType=n2-standard-8", //or n2-standard-2 with 2 workersrn "–dataflowServiceOptions=enable_streaming_engine_resource_based_billing",rn "–numWorkers=1", // or 2 workersrn "–maxNumWorkers=1", // or 2 workersrn …rn "–usePublicIps=false",rn ]rn}'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e9cc9f671f0>)])]>
The original Dataflow Streaming Engine usage is currently metered and billed based on the volume of data processed by Streaming Engine. With the resource-based billing model, jobs are metered based on the resources that are consumed and users are billed for the total resources consumed. In short, Streaming Engine Compute Units are used to calculate for “Resource Based Billing” while previously the Streaming Engine costs were calculated by the amount of data being sent/processed (Total GB of data processed).
Confirming whether the new Resource-based billing model was used
-
If you were to use “resource-based billing model”, you would be charged based on the SKU (stock keeping unit), not by the amount of streaming data processed.
-
In the “Cost” tab, you should see “Streaming Engine Compute Unit” instead of “Processed Data”.
In addition to tuning basic parameters, you can further optimize Dataflow by carefully customizing machine types to your specific workload. Dataflow Prime can also enhance both performance and cost-efficiency in some scenarios.
Optimize those Dataflow pipelines
When optimizing Dataflow pipelines, our benchmark highlights the importance of careful configuration and ongoing experimentation. The ideal setup for your Dataflow deployment is highly dependent on your specific workload, data velocity, and the cost-performance tradeoffs you’re willing to make. Understanding the various optimization tools within Dataflow – from worker configuration to features like autoscaling – is crucial for maximizing efficiency and minimizing cost.
When using resource-based billing for the two use-cases tested in this study, we found Apache Flink compute costs to be on par with Dataflow. But without this flag, Dataflow was five times more expensive — again, for the two use-cases in the scope of this study. To control costs, we highly recommend leveraging the available automated tooling.
Finally, keep an eye out for new Dataflow features! The recent introduction of at-least-once streaming mode offers greater flexibility for use cases where occasional duplicates are acceptable in favor of lower cost and reduced latency.
Ready to try Dataflow? Learn more and try it out today with a $300 credit.