
Log data has become an invaluable resource for organizations seeking to understand application behavior, optimize performance, strengthen security, and enhance user experiences. But the sheer volume and complexity of logs generated by modern applications can feel overwhelming. How do you extract meaningful insights from this sea of data?
At Google Cloud, we’re committed to providing you with the most powerful and intuitive tools to unlock the full potential of your log data. That’s why we’re thrilled to announce a series of innovations in BigQuery and Cloud Logging designed to revolutionize the way you manage, analyze, and derive value from your logs.
BigQuery pipe syntax: Reimagine SQL for log data
Say goodbye to the days of deciphering complex, nested SQL queries. BigQuery pipe syntax ushers in a new era of SQL, specifically designed with the semi-structured nature of log data in mind. BigQuery’s pipe syntax introduces an intuitive, top-down syntax that mirrors how you naturally approach data transformations. As demonstrated in the recent research by Google, this approach leads to significant improvements in query readability and writability. By visually separating different stages of a query with the pipe symbol (|>), it becomes remarkably easy to understand the logical flow of data transformation. Each step is clear, concise, and self-contained, making your queries more approachable for both you and your team.
BigQuery’s pipe syntax isn’t just about cleaner SQL — it’s about unlocking a more intuitive and efficient way to work with your data. Instead of wrestling with code, experience faster insights, improved collaboration, and more time spent extracting value.
This streamlined approach is especially powerful when it comes to the world of log analysis.
With log analysis, exploration is key. Log analysis is rarely a straight line from question to answer. Analyzing logs often means sifting through mountains of data to find specific events or patterns. You explore, you discover, and you refine your approach as you go. Pipe syntax embraces this iterative approach. You can smoothly chain together filters (WHERE), aggregations (COUNT), and sorting (ORDER BY) to extract those golden insights. You can also add or remove steps in your data processing as you uncover new insights, easily adjusting your analysis on the fly.
Imagine you want to count the total number of users who were affected by the same errors more than 100 times in the month of January. As shown below, the pipe syntax’s linear structure clearly shows the data flowing through each transformation: starting from the table, filtering by the dates, counting by user id and error type, filtering for errors >100, and finally counting the number of users affected by the same errors.
- code_block
- <ListValue: [StructValue([('code', "– Pipe Syntax rnFROM log_table rn|> WHERE datetime BETWEEN DATETIME '2024-01-01' AND '2024-01-31'rn|> AGGREGATE COUNT(log_id) AS error_count GROUP BY user_id, error_typern|> WHERE error_count>100rn|> AGGREGATE COUNT(user_id) AS user_count GROUP BY"), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e23c53e87c0>)])]>
The same example in the standard syntax will typically require using a subquery and non linear structure.
- code_block
- <ListValue: [StructValue([('code', "– Standard Syntax rnSELECT error_type, COUNT(user_id)rnFROM (rn SELECT user_id, error_type, rn count (log_id) AS error_count rn FROM log_table rn WHERE datetime BETWEEN DATETIME '2024-01-01' AND DATETIME '2024-01-31'rn GROUP BY user_id, error_typern)rnGROUP BY error_typernWHERE error_count > 100;"), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e23c53e8610>)])]>
Carrefour: A customer’s perspective
The impact of these advancements is already being felt by our customers. Here’s what Carrefour, a global leader in retail, had to say about their experience with pipe syntax:
“Pipe syntax has been a very refreshing addition to BigQuery. We started using it to dig into our audit logs, where we often use Common Table Expressions (CTEs) and aggregations. With pipe syntax, we can filter and aggregate data on the fly by just adding more pipes to the same query. This iterative approach is very intuitive and natural to read and write. We are now using it for our analysis work in every business domain. We will have a hard time going back to the old SQL syntax now!” – Axel Thevenot, Lead Data Engineer, and Guillaume Blaquiere, Data Architect, Carrefour
BigQuery pipe syntax is currently available in private preview. To sign up for a private preview please use this form and also check-out this introductory video.
Beyond syntax: performance and flexibility
But we haven’t stopped at simplifying your code. BigQuery now offers enhanced performance and powerful JSON handling capabilities to further accelerate your log analytics workflows. Given the prevalence of json data in logs, we expect these changes to simplify log analytics for a majority of users.
-
Enhanced Point Lookups: Pinpoint critical events in massive datasets quickly using BigQuery’s numeric search indexes, which dramatically accelerates queries that filter on timestamps and unique IDs. Here is a sample improvement from the announcement blog.
-
Powerful JSON Analysis: Parse and analyze your JSON-formatted log data with ease using BigQuery’s JSON_KEYS function and JSONPath traversal feature. Extract specific fields, filter on nested values, and navigate complex JSON structures without breaking a sweat.
-
JSON_KEYS extracts unique JSON keys from JSON data for easier schema exploration and discoverability
-
- JSONPath with LAX modes lets you easily fetch JSON arrays without having to use verbose UNNEST. The example below shows how to fetch all phone numbers from the person field, before and after:
- code_block
- <ListValue: [StructValue([('code', '– consider a JSON field ‘Person’ asrn[{rn "name": "Bob",rn "phone":[{"type": "home", "number": 20}, {"number":30}]rn}]rnrn–Previously, to fetch all phone numbers from ‘Person’ columnrnSELECT phone.numberrnFROM (rnSELECT IF(JSON_TYPE(person.phone) = "array", JSON_QUERY_ARRAY (person.phone), [person.phone]) as nested_phonernFrom (rnSELECT IF(JSON_TYPE(person)= "array", JSON_QUERY_ARRAY(person), [person])as nested_personrnFROM t), UNNEST(nested_person) person), UNNEST (nested_phone)phonernrn–With Lax ModernSELECT JSON_QUERY(person, "lax recursive $.phone.number") FROM t'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e23c53e8070>)])]>
Log Analytics in Cloud Logging: Bringing it all together
Log Analytics in Cloud Logging is built on top of BigQuery and provides a UI that’s purpose-built for log analysis. With an integrated date/time picker, charting and dashboarding, Log Analytics makes use of the JSON capabilities to support advanced queries and analyze logs faster. To seamlessly integrate these powerful capabilities into your log management workflow, we’re also enhancing Log Analytics (in Cloud Logging) with pipe syntax. You can now analyze your logs within Log Analytics leveraging the full power of BigQuery pipe syntax, enhanced lookups, and JSON handling, all within a unified platform.
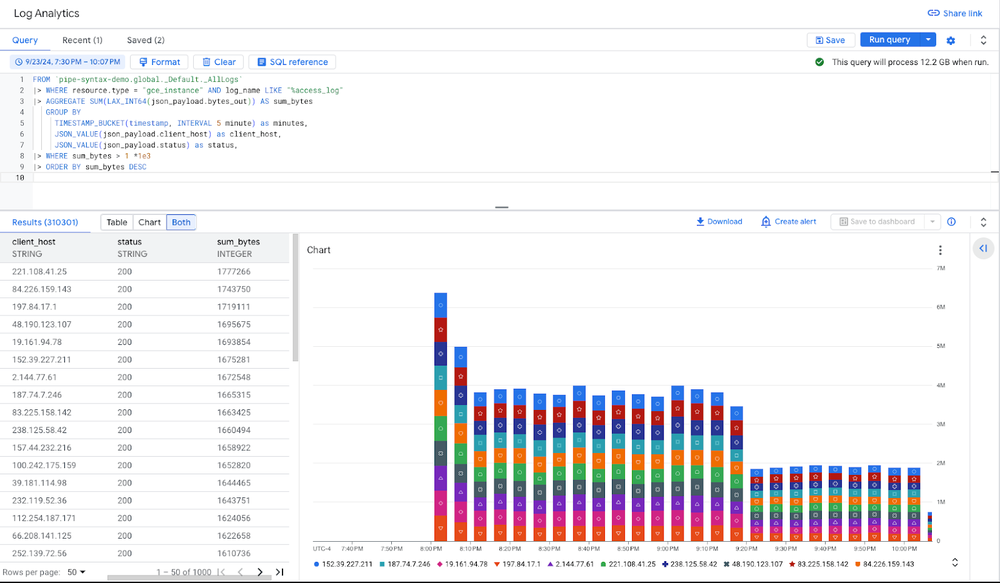
Use of pipe syntax in Log Analytics (Cloud Logging) is now available in preview.
Unlock the future of log analytics today
BigQuery and Cloud Logging provide an unmatched solution for managing, analyzing, and extracting actionable insights from your log data. Explore these new capabilities today and experience the power of:
-
Intuitive querying with pipe syntax – Introductory video, Documentation
-
Unified log management and analysis with Log Analytics in Cloud Logging
-
Blazing-fast lookups with numeric search indexes – Documentation
Start your journey towards more insightful and efficient log analytics in the cloud with BigQuery and Cloud Logging. Your data holds the answers — we’re here to help you find them.