
Vodafone is one of the largest telecommunications companies in the world, and committed to building next-generation connectivity and a sustainable digital future. Last year, we discussed AI Booster, an AI/ML platform that we built that runs on Google Cloud, and how we use it to optimize customer service, improve customer loyalty, and provide better product recommendations. Besides the benefits it brings to Vodafone’s overall operations, AI Booster is also interesting because of the way that it uses CI/CD and automation technologies. We believe this pattern has the potential to be applied to a wide range of use cases.
High-level architecture
AI Booster provides an opinionated abstraction around Google Cloud services (especially Vertex AI), ensuring automation and security guardrails. At the same time, we worked to drive efficiency, reduce operational overhead and deployment time in AI Booster by automating steps such as CI/CD and code mirroring, which significantly reduced our application delivery times while helping to keep data secure.
AI Booster consists of several projects, and connects to various core Vodafone services. Let’s take a closer look.

The Datahub
An important part of the overall AI Booster environment is the Datahub, Vodafone’s data lake, one of our most precious and valuable data vaults. Built on BigQuery, the Datahub is divided into local markets, and is the source for all the data used in our AI/ML use cases. Access to it is vetted by each data segment’s respective owners, and each local market uses a different project to enforce additional segregation. Vodafone’s Data Science teams get read-only access to the production data they need for a particular use case.
AI Booster
AI Booster itself consists of five projects per use case, each with a distinct purpose. Three of those projects are fairly typical environments:
-
LAB: A development environment where data scientists can create and iterate their models. Scratch storage will be used in R/W and wiped every 14 days for compliance reasons.
-
STAGING: The staging/pre-production staging area. It has the same storage setup as the LAB environment.
-
PROD: The production environment with R/W access to the production Datahub.
In addition, there are two auxiliary Google Cloud projects, which are used for build purposes:
-
BuildSTAGING: Cloud Build, from LAB to STAGING
-
BuildPROD: Cloud Build, from STAGING to PROD
The entire setup including all environments is created upon request in Vodafone’s workflow tool. The workflow integrates privacy and responsible AI governance processes and requires approval from respective stakeholders for the use case or project before deploying the resources. “Once the approval is granted, the workflow tool triggers the creation process using Terraform, spinning up all Google Cloud projects, service accounts, VPC/networking, etc. and leveraging Google Cloud Build. The architecture has security built in, e.g., using VPC-SC, CMEK, Cloud NAT, and there is no access to public internet,” says Omotayo Aina, Solution Architect at Vodafone Group Technology.
Central mirror and repositories
Whenever Vodafone data scientists or ML engineers need to access any libraries, packages, or containers, they actually receive them from a central mirror. The central mirror is a key component of the AI Booster architecture, providing vetted artifacts (from Artifact Registry) and making for fast and easy retrieval. The central mirror consists of:
-
PYPI mirror: Python libraries local mirror
-
hub.docker.com mirror that pulls from public docker repos (such as Mongo)
-
Container store: Containers you can use to spin up notebooks or Vertex AI pipelines
For added security, all artifacts are scanned, and any “compromised” versions are flagged centrally, preventing developers from pulling vulnerable artifacts. Projects that require vulnerable (flagged) artifacts must look for an alternative artifact version with no vulnerabilities. If it’s not feasible to replace an artifact, we perform a review of the residual risk and mitigate it before granting an approval. A NAT/firewall configuration prevents developers from using the original repositories outside the Vodafone network, ensuring they only use mirrored artifacts.
AI Booster at work: Predicting churn in two different markets
Vodafone operates in 17 countries, mostly in Europe. Recently, Vodafone Group’s Big Data & AI team was tasked with building customer churn prediction models for some of these countries, but found it was a complex task.
“Each local market has its own set of requirements, and different data dimensions are available per country. Yet, we want to quickly replicate our work across markets,” said Ali Cabukel, a Vodafone Machine Learning Engineer. “AI Booster enables us to achieve this much more easily.”
To understand the AI Booster architecture better, and how it helped improve our operations, let’s start with a real use case: predicting customer churn for one local market, and then replicating it for another local market.
1. LAB environment: development
A data scientist (DS) starts off in the LAB environment. Here they have access to:
-
Local Datahub (BigQuery) with access to Customer Analytical Records (CAR), which are wide tables with bills, calls, data usage and other customer data specific to a local market
-
A private GitHub repository for each use case
-
A number of Google Cloud tools within AI Booster, e.g, Vertex AI, BigQuery, and BigQuery ML
Data scientists spend their time with data preparation, pre-processing, feature selection, and building models using frameworks like BQML, Spark ML (serverless), XGBoost, LightGBM, scikit-learn, TensorFlow, and Google’s AutoML. All code is regularly checked into a GitHub repository as a best practice.
To accelerate the work, there is a central template repository that contains Cloud Build configuration files, Kubeflow Pipelines (KFP), pre-built (reusable) KFP components, Build Triggers, unit tests, payload files, queries, and dependency requirements files. Here is a sample repository that’s publicly available from Google Cloud.
As we refine the use case, the ability to perform several parallel experiments with data becomes a priority; for that, data scientists and machine learning engineers need to be able to quickly create a training pipeline in Vertex Pipelines, leveraging the assets provided in the template repository.

2. From LAB to STAGING
Once the LAB environment is considered stable, the KFP pipeline is promoted to STAGING, so data scientists and machine learning engineers can start integration testing any changes that they first implemented in the LAB environment.
How does this happen? The BuildSTAGING Cloud Build pipeline transfers code and pipelines to the STAGING environment, where data scientists check for data errors and pipeline behavior, and set up proper triggers in Cloud Scheduler, Pub/Sub, and Cloud Functions. To deploy the Kubeflow pipeline to STAGING, CI/CD Github triggers are set up on the BuildSTAGING Google Cloud project using Cloud Build. Specifically,
-
pr-checkstests the Pull Request for linting, unit tests, and catchable errors -
terraform-planverifies the Terraform desired config “compiles”
Then, after some back and forth where code is linted, tested, and finally approved, the code is actually merged. That, in turn, sets off another two triggers:
-
terraform-apply: this trigger actually applies the infrastructure changes via Terraform, including time-based scheduling (cron jobs) to Cloud Scheduler on the STAGING/PROD project -
release: the release trigger is fired with a new GitHub release tag (versioning). This trigger is responsible for compiling the Kubeflow pipelines, transferring all resources to a Cloud Storage bucket and conducting end-to-end tests.
3. From STAGING to PROD
Finally, the model is pushed to PROD and is now able to read/write data to the Vodafone DataHub. How? Similar to the previous step, the BuildPROD project promotes the pipeline structure from STAGING to PROD. The structure between STAGING and PROD is identical, with the only difference that the production environment has write access to the production DataHub, whereas the previous stages only have r/w access to an ephemeral local copy.
4. And back to LAB…
Let’s say that a data scientist now wants to do similar work for another local market. While the data might look different and some experimentation is required, there are likely many similarities between the two, including the pipeline. As such, moving to STAGING and PROD will be much faster. The overall process will look like this:
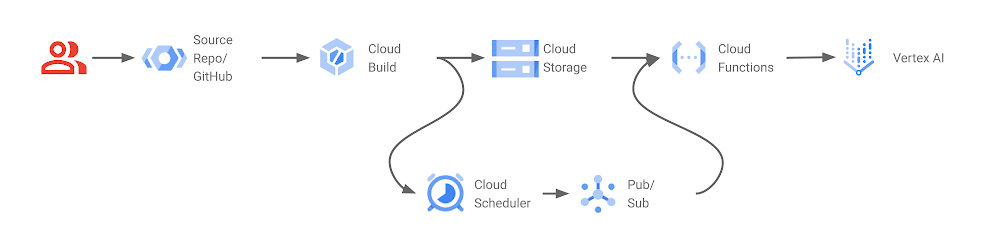
5. Change management
AI Booster uses TensorFlow Data Validation to identify data skew between training and prediction data. This tool is very useful for catching data anomalies with respect to data distributions. If needed, the data scientist goes back to LAB to fix the problem; changes are then propagated quickly to production. You can read a more in-depth view of how we use TensorFlow Data Validation in our data contracts in this TensorFlow blog post.
Results and improvements
As a result of using AI Booster, we see multi-fold improvements – most notably efficiency gains:
-
Reduced time to market (5x): We found a robust, repeatable and trustworthy toolchain to allow our data scientists to be successful on the platform, without having to compromise between data security and flexibility in experimentation
-
Improved maintenance and data quality: By leveraging more automation and standardization, we were able to ensure common quality standards and thus also reduce maintenance efforts over the lifecycle of a use case.
-
More flexibility: Deployment frequency has increased by ~5x (from one pipeline in a month to five in a month). This gives us the flexibility to react quickly to changes and work in an agile way.. In many cases, we’ve removed extensive reviews and alignments from the process entirely, as security and compliance are baked in.
-
Improved compliance processes: Integrating privacy and responsible AI requirements early on in the development processes helps to ensure a “by design” approach and address the topics in the right time of the development lifecycle.
At Vodafone, our main objective is to empower data science teams to focus on customers. Overall, the lightweight AI Booster wrapper makes it easy for central or distributed teams to evolve the platform and handle maintenance efficiently. We are excited to continue evolving AI Booster in the future..
Thanks to Max Vökler, Technical Account Manager, for his contributions to this post.