
Apache Airflow is a popular tool for orchestrating data workflows. Google Cloud offers a managed Airflow service called Cloud Composer, a fully managed workflow orchestration service built on Apache Airflow that enables you to author, schedule, and monitor pipelines.
Despite Airflow’s popularity and ease of use, the nuances of DAG (Directed Acyclic Graph) and task concurrency can be intimidating, given the different components and numerous configuration settings in an Airflow installation. Understanding and implementing concurrency strategies optimizes resource utilization, improves scalability, and improves fault-tolerance in your data pipelines. This guide aims to provide everything you need to know about Airflow concurrency across four levels:
-
Composer Environment
-
Airflow Installation
-
DAG
-
Task
Visualizations in each section help you understand which settings need to be adjusted to ensure your Airflow tasks run exactly the way you intend. Let’s get started!
1. Cloud Composer 2 environment level settings
This is the Google Cloud service as a whole. It includes all the managed infrastructure required to run Airflow as well as integrations with other Google Cloud services such as Cloud Logging and Cloud Monitoring. Configurations at this level will be inherited by the Airflow installation, DAGs, and Tasks.

Worker min/max count
When building a Cloud Composer environment, you’ll specify the min/max counts of Airflow Workers, as well as the Worker size (cpu, memory, storage). These configurations will determine the default value of worker_concurrency.
Sample terraform:
- code_block
- <ListValue: [StructValue([('code', 'resource "google_composer_environment" "composer2" {rn provider t= google-betarn name t= "${var.composer_environment_name}"rn project t= var.project_idrn region t= var.regionrn config {rn tworkloads_config {rn ttworker {rn ttcpu tt= 0.5rn ttmemory_gb t= 2rn ttstorage_gb t= 15rn ttmin_count t= 1rn ttmax_count t= 3rn tt}rn}rn}rn}'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e4a7c7afb80>)])]>
Worker concurrency
A Worker with one CPU can typically handle 12 concurrent tasks. On Cloud Composer 2, the default value for worker concurrency is equal to:
-
In Airflow 2.3.3 and later versions, a minimum value out of 32, 12 * worker_CPU, and 8 * worker_memory.
-
In Airflow versions before 2.3.3, 12 * worker_CPU.
For example:
Small Composer environment:
-
worker_cpu = 0.5
-
worker_mem = 2
-
worker_concurrency = min(32, 12*0.5cpu, 8*2gb) = 6
Medium Composer environment:
-
worker_cpu = 2
-
worker_mem = 7.5
-
worker_concurrency = min(32, 12*2cpu, 8*7.5gb) = 24
Large Composer environment:
-
worker_cpu = 4
-
worker_mem = 15
-
worker_concurrency = min(32, 12*4cpu, 8*15gb) = 32
Worker autoscaling
Concurrency performance and your environment’s ability to autoscale is connected to two settings:
-
the minimum number of Airflow workers
-
the [celery]worker_concurrency parameter
Cloud Composer monitors the task queue and spawns additional workers to pick up any waiting tasks. Setting [celery]worker_concurrency to a high value means that every worker can pick up a lot of tasks, so under certain circumstances the queue might never fill up, causing autoscaling to never trigger.
For example, in a Cloud Composer environment with two Airflow workers, [celery]worker_concurrency set to 100, and 200 tasks in the queue, each worker would pick up 100 tasks. This leaves the queue empty and doesn’t trigger autoscaling. If these tasks take a long time to complete, this could lead to delayed results as other tasks wait for available worker slots.
An alternative way to look at it: the way Composer’s scaling works is that it looks at a sum of Queued Tasks and Running Tasks, then it divides this number by [celery]worker_concurrency and does a ceiling() from the result. If there are 11 tasks in the Running state and 8 tasks in the Queued state while [celery]worker_concurrency is set to 6, the target number of workers is ceiling((11+8)/6) = 4. Composer will attempt to scale the number of workers to 4.
2. Airflow installation level settings
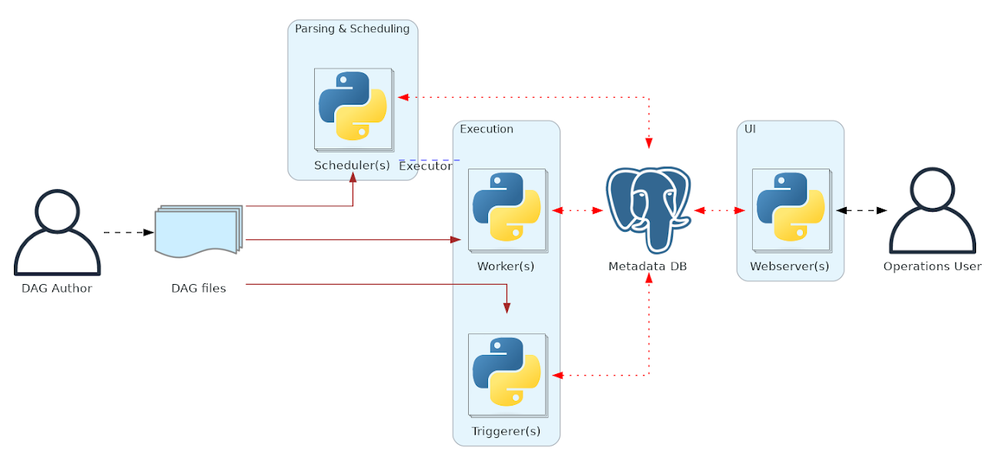
This is the Airflow installation being managed by Cloud Composer. It includes all Airflow components such as Scheduler, DAG Processor, Web Server, Workers, and Metadata database. This level will inherit configurations at the Composer level if not already set.
[celery]worker_concurrency: The default values provided by Cloud Composer are optimal for the majority of use cases, but your environment might benefit from custom adjustments.
core.parallelism: maximum number of tasks running across an entire Airflow installation. parallelism=0 means infinite.
core.max_active_runs_per_dag: maximum number of active DAG runs, per DAG
core.max_active_tasks_per_dag: maximum number of active DAG tasks, per DAG
Queues
When using the CeleryExecutor, the Celery queues that tasks are sent to can be specified. Queue is an attribute of BaseOperator, so any task can be assigned to any queue. The default queue for the environment is defined in the airflow.cfg’s celery -> default_queue. This defines the queue that tasks get assigned to when not specified, as well as which queue Airflow workers listen to when started.
Pools
Airflow pools can be used to limit the execution parallelism on arbitrary sets of tasks. The list of pools is managed in the UI (Menu -> Admin -> Pools) by giving the pools a name and assigning it a number of worker slots. There you can also decide whether the pool should include deferred tasks in its calculation of occupied slots.
3. DAG level settings
A DAG is the core concept of Airflow, collecting Tasks together, organized with dependencies and relationships to say how they should run.
max_active_runs: maximum number of active runs for this DAG. The scheduler will not create new active DAG runs once this limit is hit. Defaults to core.max_active_runs_per_dag if not set
max_active_tasks: the number of task instances allowed to run concurrently across all active runs of the DAG this is set on. If this setting is not defined, the value of the environment-level setting max_active_tasks_per_dag is assumed.
- code_block
- <ListValue: [StructValue([('code', "# Allow a maximum of 10 tasks to be running across a max of 2 active DAG runsrndag = DAG(rn'example2', rnmax_active_tasks=10,rnmax_active_runs=2rn)"), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e4a7c7afd30>)])]>
4. Task level settings
About Airflow Tasks
The possible states for a Task Instance are:
-
none: The Task has not yet been queued for execution (its dependencies are not yet met).
-
scheduled: The scheduler has determined the Task’s dependencies are met and it should run.
-
queued: The task has been assigned to an Executor and is awaiting a worker.
-
running: The task is running on a worker (or on a local/synchronous executor).
-
success: The task finished running without errors.
-
restarting: The task was externally requested to restart when it was running.
-
failed: The task had an error during execution and failed to run.
-
skipped: The task was skipped due to branching, LatestOnly, or similar.
-
upstream_failed: An upstream task failed and the Trigger Rule says we needed it.
-
up_for_retry: The task failed, but has retry attempts left and will be rescheduled.
-
up_for_reschedule: The task is a Sensor that is in reschedule mode.
-
deferred: The task has been deferred to a trigger.
-
removed: The task has vanished from the DAG since the run started.

Ideally, a task should flow from none, to scheduled, to queued, to running, and finally to success. Tasks will inherit concurrency configurations set at the DAG or Airflow level unless otherwise specified. Task specific configurations include:
pool: the pool to execute the task in. Pools can be used to limit parallelism for only a subset of tasks
max_active_tis_per_dag: controls the number of concurrent running task instances across dag_runs per task.
- code_block
- <ListValue: [StructValue([('code', "t1 = BaseOperator(rnttask_id='sample'rnpool='my_custom_pool',rnmax_active_tis_per_dag=12rn)"), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e4a7c7af9a0>)])]>
Deferrable Operators and Triggers
Standard Operators and Sensors take up a full worker slot for the entire time they are running, even if they are idle; for example, if you only have 100 worker slots available to run Tasks, and you have 100 DAGs waiting on a Sensor that’s currently running but idle, then you cannot run anything else — even though your entire Airflow cluster is essentially idle.
This is where Deferrable Operators come in.
A deferrable operator is one that is written with the ability to suspend itself and free up the worker when it knows it has to wait, and hand off the job of resuming it to something called a Trigger. As a result, while it is suspended (deferred), it is not taking up a worker slot and your cluster will have a lot less resources wasted on idle Operators or Sensors. Note that by default deferred tasks will not use up pool slots, if you would like them to, you can change this by editing the pool in question.
Triggers are small, asynchronous pieces of Python code designed to be run all together in a single Python process; because they are asynchronous, they are able to all co-exist efficiently. As an overview of how this process works:
-
A task instance (running operator) gets to a point where it has to wait, and defers itself with a trigger tied to the event that should resume it. This frees up the worker to run something else.
-
The new Trigger instance is registered inside Airflow, and picked up by a triggerer process.
-
The trigger is run until it fires, at which point its source task is rescheduled.
-
The scheduler queues the task to resume on a worker node
Sensor modes
Because they are primarily idle, Sensors have two different modes of running so you can be a bit more efficient about using them:
poke (default): The Sensor takes up a worker slot for its entire runtime
reschedule: The Sensor takes up a worker slot only when it is checking, and sleeps for a set duration between checks. Reschedule mode for Sensors solves some of this, allowing Sensors to only run at fixed intervals, but it is inflexible and only allows using time as the reason to resume, not anything else.
Alternatively, some sensors allow you to set deferrable=True which further improves resource utilization by offloading processes to a separate Triggerer component.
Difference between mode=’reschedule’ and deferrable=True in Sensors
In Airflow, Sensors wait for specific conditions to be met before proceeding with downstream tasks. Sensors have two options for managing idle periods: mode=’reschedule’ and deferrable=True. As mode=’reschedule’ is a parameter specific to the BaseSensorOperator in Airflow, which allows the sensor to reschedule itself if the condition is not met, whereas, deferrable=True is a convention used by some operators to indicate that the task can be retried (or deferred) later, but it is not a built-in parameter or mode in the Airflow. The actual behavior of retrying the task may vary depending on the specific operator implementation.
Concurrency limiters
Here is an illustration of how different configuration settings can interact to limit the number of concurrent DAG runs or tasks:
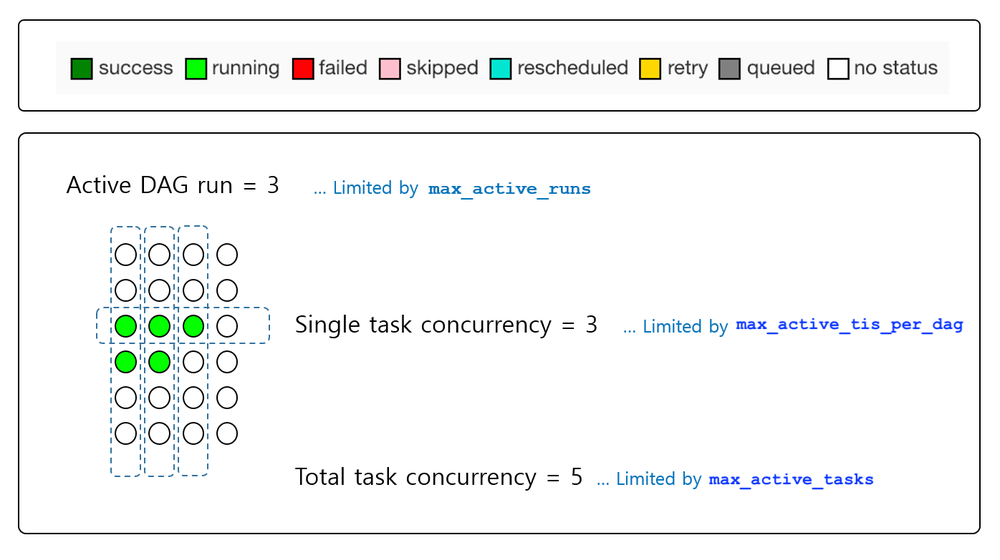
Summary
From top to bottom, these are the configurations that will provide full control over concurrency on Cloud Composer.
Composer environment
worker min/max count: more workers = more tasks that can be performed concurrently.
Airflow installation
worker_concurrency: higher concurrency = more tasks that get picked up by an individual worker. High value means that every worker can pick up a lot of tasks, so under certain circumstances the queue might never fill up, causing autoscaling to never trigger. Use Composer’s default value for most cases.
parallelism: maximum number of tasks running across an entire Airflow installation. parallelism=0 means infinite.
max_active_runs_per_dag: maximum number of active DAG runs, per DAG.
max_active_tasks_per_dag: maximum number of active DAG tasks, per DAG.
DAG
max_active_runs: maximum number of active runs for this DAG. The scheduler will not create new active DAG runs once this limit is hit. Defaults to core.max_active_runs_per_dag if not set.
max_active_tasks: the number of task instances allowed to run concurrently across all active runs of the DAG this is set on. If this setting is not defined, the value of the environment-level setting max_active_tasks_per_dag is assumed.
Task
max_active_tis_per_dag: controls the number of concurrent running task instances across dag_runs per task.
Troubleshooting scenarios
Scenario: Composer Environment frequently reaches maximum limits for workers, number of tasks in queue is consistently high, and DAGs do not meet their SLAs.
Solution: You can increase the number of workers in your Cloud Composer environment or introduce higher autoscaling min/max values.
Scenario: There are long inter-task scheduling delays, but at same time the environment does not scale up to its maximum number of workers
Solution: Increase worker concurrency ( [celery]worker_concurrency ). Worker concurrency must be set to a value that is higher than the expected maximum number of concurrent tasks, divided by the maximum number of workers in the environment.
Scenario: You run the same DAG many times in parallel, causing Airflow to throttle execution.
Solution: Increase max active runs per DAG (max_active_runs_per_dag, max_active_runs)
Scenario: A single DAG is running a large number of tasks in parallel, causing Airflow to throttle task execution
Solution: Increase DAG concurrency (max_active_tasks_per_dag, max_active_tasks) if you want to complete the single DAG as fast as possible. Decrease that DAG’s max_active_tasks value, or the environment level max_active_tasks_per_dag if you’d like other DAGs to run at the same time . Also, check to see if parallelism is not set to 0 (infinity).
Scenario: A single DAG is running the same task many times in parallel, causing Airflow to throttle the execution of that task.
Solution: Increase task concurrency. (max_active_tasks_per_dag, max_active_tasks, max_active_tis_per_dag)
Scenario: Tasks aren’t running at the same time.
Solution: In Airflow, parallelism depends on what resources are available to the airflow worker / airflow scheduler AND what your environment configuration is. There’s no guarantee that tasks will run at exactly the same time. All you can ensure is that Task A,B,C will complete before Task D
Scenario: Tasks are being throttled.
Solution: Check the Concurrency Limiters chart above and make a note of your current configurations.
Scenario: Sensors are taking up too many worker slots.
Solution: Sensor checking every n seconds (i.e. poke_interval < 60)? Use mode=poke. Sensor checking every n minutes (i.e. poke_interval >= 60)? Use mode=reschedule. A sensor in mode=reschedule will free up Airflow worker resources between poke intervals. For even better performance, opt to use deferrable=True for your Sensors. This will ignore the sensor mode and instead pass the poke_interval and process to the Airflow Triggerer, freeing up Airflow Worker resources for other tasks.
Next steps
Mastering Airflow DAG and task concurrency is essential for unlocking the full potential of Cloud Composer. By understanding the core concepts, configuring your environment effectively, and employing practical optimization strategies, you can orchestrate even the most complex data pipelines with confidence. For more information about Cloud Composer
To learn more about Cloud Composer, Apache Airflow, and the information discussed in this guide, consider exploring the following resources: