Editor’s Note: Flipkart, a major Indian e-commerce platform, partnered with Google Cloud to enhance its technology infrastructure and support future growth. One of the key steps in the company’s journey was migrating its streaming analytics infrastructure from Apache HBase to Bigtable, which improved developer productivity, database performance, and its responsiveness to big fluctuations in customer demand — with minimal code changes.
In the vibrant world of Indian e-commerce, Flipkart stands as a beacon, catering to over 450 million users and hosting 1.4 million sellers. This mammoth marketplace offers a staggering variety of 150 million products and facilitates millions of shipments daily.
The crown jewel of Flipkart’s calendar is the Big Billion Day (BBD) Sales, akin to the global shopping extravaganzas Black Friday and Cyber Monday. The Big Billion Day Sales spans many days in September and October, coinciding with India’s vibrant festival season. During this period, Flipkart experiences a transaction volume surge of six to eight times the ordinary business-as-usual (BAU) volume.
Flipkart was looking to reshape its technological landscape and future-proof its operations. Thus began the partnership with Google Cloud, which is already bearing fruit with the successful launch of the pivotal platform: Flipkart Data Platform (FDP).
fStream: Flipkart’s streaming platform
At the core of Flipkart’s data operations lies fStream, its in-house common streaming platform. fStream operates seamlessly on Apache Spark and Apache Flink using Dataproc.
One of fStream’s integral components is a durable StateStore, which serves as the persistence layer for various critical functions, including:
-
Indexing: Storing incoming streaming data in StateStore to enable joining with other streams based on specific keys.
-
Joining: Matching and merging data from two or more streaming sources based on a common key, producing a combined output for further processing or storage. This includes mandatory joins for handling late-arriving data and associated metadata stored in StateStore for out-of-order processing.
-
Aggregating: Storing aggregates across multiple keys, dimensions, and time-buckets. Aggregating serves a dual purpose — storing intermediate data for processing in other fStream pipelines as well as final data queried by the fStream API to generate real-time reports.
-
Checkpointing: Maintaining external checkpoints for sources, such as Kafka.
-
Deduplicating: Identifying and removing duplicate records from a streaming data source, ensuring that only unique records are retained for further processing or storage.
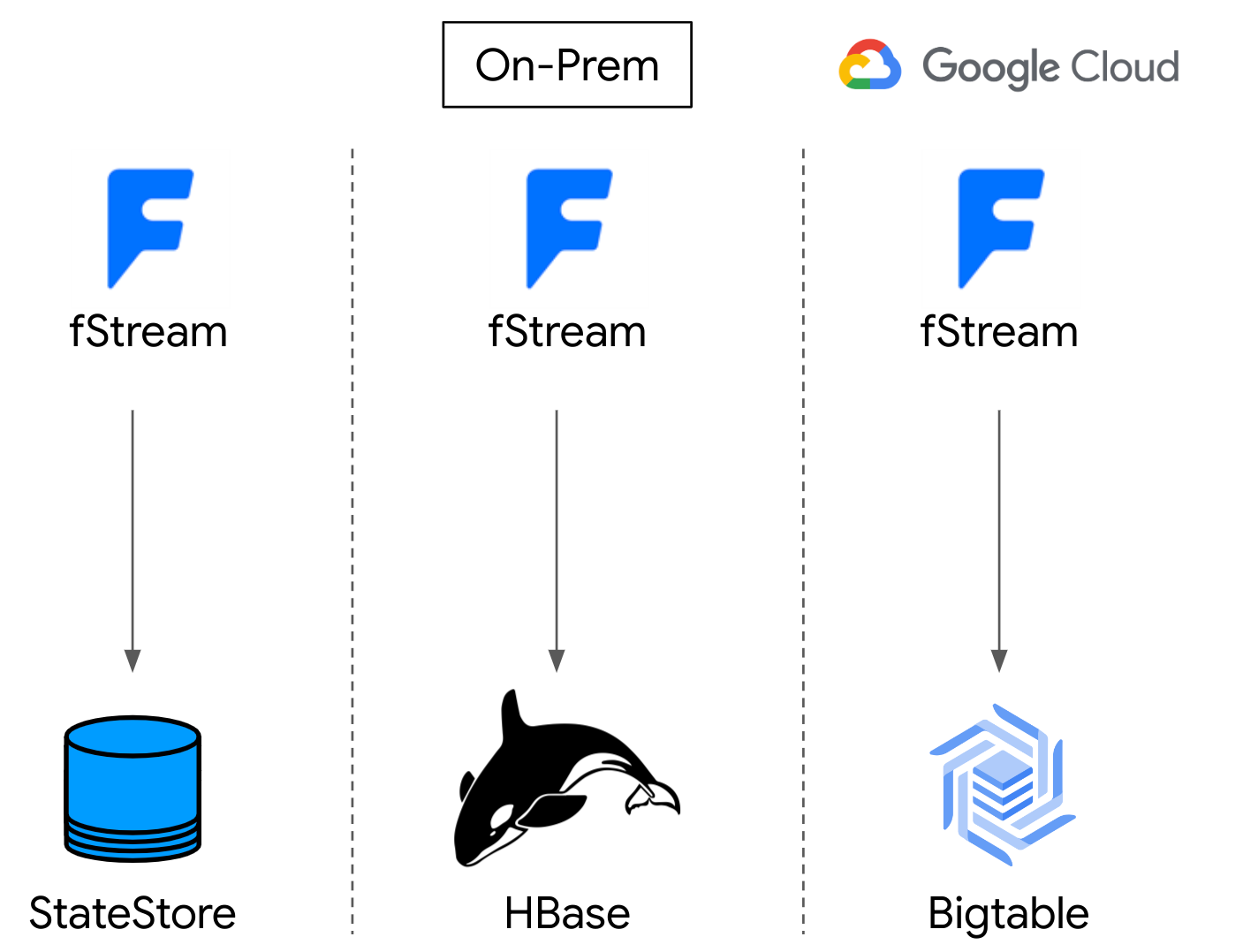
Fig 1.: Statestore for stateful stream processing pipelines
In its on-premises deployment, Flipkart used Apache HBase as its StateStore due to its robust capabilities. However, when migrating to Google Cloud, Flipkart wanted to be able to leverage the cloud-native functionalities of Bigtable. As a result, the team undertook the effort to migrate from HBase to Bigtable to fully utilize Google Cloud’s advanced features and scalability.
Migration process overview
Due to the complex and critical nature of the functions provided by Apache HBase, migrating to Bigtable was a meticulous process involving several crucial steps:
-
Taking a snapshot of HBase cluster table.
-
Copying the snapshot to the same HDFS cluster in a different directory using HBase Utility (MapReduce Job).
-
Transfering the snapshot data to a Cloud Storage bucket using the HBase Utility and the gcs-hadoop connector (MapReduce Job).
-
Creating a destination table in Bigtable with the required schema and configurations.
-
Importing the Cloud Storage snapshot data into Bigtable using Bigtable’s HBase migration tool via Dataflow.
-
Verifying the row/region level hash between the snapshot and Bigtable to ensure complete data migration.
Flipkart’s data ecosystem also involved intricate pipeline dependencies, making the migration process even more complex. Various pipeline types, such as Index, Join, and Aggregate posed unique migration challenges. For example, as real-time processes, these pipelines needed to remain operational without any downtime, even during the window of migration. The data also had to be processed precisely once (e.g., exactly once aggregates) across both setups to prevent problems, such as double counting in aggregate pipelines and serving late arriving data in join pipelines.
The following outlines Flipkart’s high-level solutions for migrating these pipelines.
Index pipelines
To start the migration process, Flipkart replicated the Kafka source topic to Pub/Sub. Simultaneously, the team would capture a snapshot of the HBase table containing the essential dataset and then transfer it to Bigtable. Subsequently, the team initiated the index pipeline in Google Cloud, starting with the earliest available message in Pub/Sub. This marked the beginning of the data processing journey in the new environment.
Google Cloud provides tooling for near zero downtime migration from HBase to Bigtable, via a HBase replication library. However, Flipkart’s final architecture required the indexing pipeline running on Google Cloud, so it was more efficient operationally to use the pipeline for replication, keeping the two datasets in sync while the HBase snapshot was being copied.
Aggregate pipelines
To migrate an aggregate pipeline, Flipkart paused the existing pipeline in its platform and captured a snapshot of the HBase table, recording the source Kafka checkpoints. If it was necessary to continue operating without any downtime, the original aggregate pipeline would then be restarted. From there, the HBase aggregate table was transferred to Bigtable. Next, the team initiated a parallel pipeline in Google Cloud to read data from Kafka and write it into Bigtable. They applied a filter for the “ingestedAt” timestamp to ensure that any data before “someTimestamp” was included. The recorded Kafka checkpoints were then used to guarantee that all data until “someTimestamp” was properly aggregated in Bigtable. After that, they started the aggregate pipeline in Google Cloud, using a filter (“ingestedAt” > someTimestamp) to read data from PubSub and take over processing, either from the end of the copied data or from a specified future date.
Here are the steps taken to complete the aggregate pipeline migration:
-
Pause the aggregate pipeline running on HBase.
-
Capture a snapshot of the HBase table and record the source Kafka checkpoints.
-
Restart the aggregate pipeline if it’s necessary to continue operations.
-
Transfer the HBase aggregate table to Bigtable.
-
Initiate a parallel aggregate pipeline in Google Cloud that reads data from Kafka and writes it into Bigtable. Apply a filter based on the “ingestedAt” timestamp, ensuring data before “someTimestamp” is included.
-
Use the checkpoint obtained in Step 2 as the source checkpoint for this Kafka job. This guarantees that all data until “someTimestamp” is properly aggregated in BigTable.
-
Start the aggregate pipeline in Google Cloud with a reverse “ingestedAt” filter ( > someTimestamp). This pipeline reads data from PubSub and takes over processing from the “someTimestamp,” which can be set to a future date (for instance, one day ahead).
Join pipelines
For non-mandatory joins, no specific migration solution was required. For a mandatory join, the approach was similar to the one described above for Aggregate pipelines, as fStream syncs support idempotence. To migrate mandatory join pipelines, Flipkart would start an index pipeline migration and wait for it to complete. The team would then pause the pipeline, capture a snapshot of the Hbase table, and transfer it to Bigtable. If necessary, mandatory joins would be restarted to safeguard normal operations. A parallel pipeline would then be initiated in Google Cloud, which would eventually take over processing once all the data had been read and written over into Bigtable.
In conclusion
Overall, The migration process for pipelines interacting with Bigtable was a success story: 70% of pipelines, managing idempotent data, transitioned seamlessly ensuring uninterrupted operation. For the remaining 30% of pipelines dealing with non-idempotent data, a one time restart was required, causing only minimal downtime. This strategic approach ensured a smooth transition for the entire spectrum of pipelines, guaranteeing continuity and efficiency.
-
Start the index pipeline migration.
-
Wait for completion of the index pipeline migration.
-
Perform the same steps [1-7] as aggregate pipeline for Join Pipeline Migration.
Both Flipkart and Google Cloud pipelines could coexist temporarily, accepting duplicate processing if necessary.
Advantages of Bigtable over HBase for Flipkart
Flipkart’s transition to Bigtable has brought unprecedented efficiency and flexibility, ensuring a seamless shopping experience for their millions of customers.
Bigtable’s auto-scaling policies enabled Flipkart to optimize its resource use, ensuring resource and cost efficiency. Scaling up or down is simplified with a single click in the user interface, enhancing the resource management experience — the platform scaled up 4X during its Big Billion Day event with no capacity concerns or performance impact. It also enables decoupling of compute and storage, ensuring faster load rebalancing to further enhance performance.
Even better, the seamless transition to Bigtable from HBase required minimal changes in code. Bigtable provides enhanced user experience with its compatible HBase Shell interface that facilitates effortless interactions for both platform and user teams. Plus, it provides detailed metrics and tools like Key Visualizer to enable effective troubleshooting.
Another benefit of moving to Bigtable is that it shields Flipkart from maintenance activities and removes many operational complexities, saving developer bandwidth. For example, Bigtable offers more efficient replication between clusters, ensuring a seamless and trouble-free experience. It also offers robust instance-level isolation, which ensures that issues in a single table never cause cluster wide disturbances.
Flipkart’s journey serves as a testament to the transformative power of embracing cutting-edge technology, paving the way for a future where data management is not only efficient but also inspiring.
Interested in migrating from HBase? Learn more about how to migrate your data from HBase to Bigtable.
Many thanks to Robin Chugh, Architect, Data Platform, Flipkart, who contributed heavily to this post.