Want to make ultra-fast ML predictions without writing and maintaining siloed applications, or having to move your data? How about doing it all with just SQL queries, and without worrying about scaling, security, or performance? Google Cloud Spanner, a globally distributed and strongly consistent database, has revolutionized the way organizations store and manage data at any scale transparently and securely. Vertex AI has transformed how we use data and gain meaningful insights and make informed decisions with machine learning, artificial intelligence and generative AI. Spanner with its Vertex AI integration helps you perform predictions using your transactional data with models deployed in Vertex AI easier and faster than before.
This means you can eliminate the need to access Cloud Spanner data and the Vertex AI endpoint separately. Traditionally, we would retrieve data from the database and pass it to the model via different modules of the application, or external service/function, then serve it to the end-user or write-back to the database. The win here is that you don’t have to use the application layer to combine these results anymore, it’s all rolled into one step in the Spanner database, right where your data lives using familiar SQL.
The benefits of Spanner with Vertex AI integration include:
Improved performance and better latency: Spanner talking directly to the Vertex AI service eliminates additional round-trips between the Spanner client and the Vertex AI service.
Better throughput / parallelism: Spanner Vertex AI integration runs on top of Cloud Spanner’s distributed query processing infrastructure, which supports highly parallelizable query execution.
Simple user experience: Ability to use a single, simple, coherent, and familiar SQL interface to facilitate both data transformation and ML serving scenarios on Cloud Spanner scale lowers the ML entry barrier and allows for a much smoother user experience.
Reduced costs: Spanner Vertex AI integration uses Cloud Spanner compute capacity to merge the results of ML computations and SQL query execution, which eliminates the need to provision an additional compute.
In this blog, we will explore the steps to perform ML predictions from Spanner using a model deployed in Vertex AI. This is possible by registering the ML model in Spanner that has already been deployed to a Vertex AI endpoint.
Use case
For implementing this feature, we will take my good-old movie viewer score prediction use case for which we already have the model created in both Vertex AI and BQML methods. The movie score model predicts the success score of a movie (in other words, an IMDB rating) on a scale of 1 to 10 depending on various factors including runtime, genre, production company, director, cast, cost, etc. The steps to create this model are available as codelabs and the links are included in the next section of this blog.
Prerequisites
- Google Cloud project: Before you begin, make sure you have a Google Cloud project created, billing enabled, set up Spanner access control to access Vertex AI endpoint provisioned, and necessary APIs (BigQuery API, Vertex AI API, BigQuery Connection API) enabled.
- ML model: Familiarize yourself with the movie prediction model creation process using Vertex AI Auto ML or BigQuery ML by referring to the codelabs linked here or here.
- Deployed ML model: Have the movie score prediction model created and deployed in Vertex AI endpoint. You can refer to this blog for guidance on creating and deploying the model.
- There will be costs associated with implementing this use case. If you want to do this for free, use the BQML model deployed in Vertex AI and choose Spanner free-tier instance for the data.
Implementation
We will predict the movie success score for data in Cloud Spanner using the model created with Vertex AI Auto ML and deployed in Vertex AI.
Below are the steps:
Step 1: Create a Spanner Instance
- Go to Google Cloud console, search for Spanner and choose the Spanner product.
- You can create an instance or choose the free instance.
- Provide instance name, ID, region and standard configuration details. Let’s select the region to be the same as your Vertex / BigQuery datasets. In my case, this is us-central1. Let’s call this instance spanner-vertex.

Step 2: Create a database
- From the instance page, you should be able to create a database by providing the database name and database dialect (select Google Standard SQL). You could also optionally create a table there, but let’s reserve that for the next step. Go ahead and click CREATE.

Step 3: Create a table
- After the database is created, navigate to the database overview page.
- Click CREATE TABLE button, paste the below statement in the DDL TEMPLATES section and execute:
CREATE TABLE movies (
id INT64,
name STRING(100),
rating STRING(50),
genre STRING(50),
year FLOAT64,
released STRING(50),
score FLOAT64,
director STRING(100),
writer STRING(100),
star STRING(100),
country STRING(50),
budget FLOAT64,
company STRING(100),
runtime FLOAT64,
data_cat STRING(10),
) PRIMARY KEY (id);

Step 4: Insert test data
- Now that we have created the table, let’s insert a few records to use as test data in the table we just created.
- Go to the database overview page, and from the list of tables available, click movies.
- In the TABLE page, click Spanner Studio in the left pane and this should open the studio on the right side.
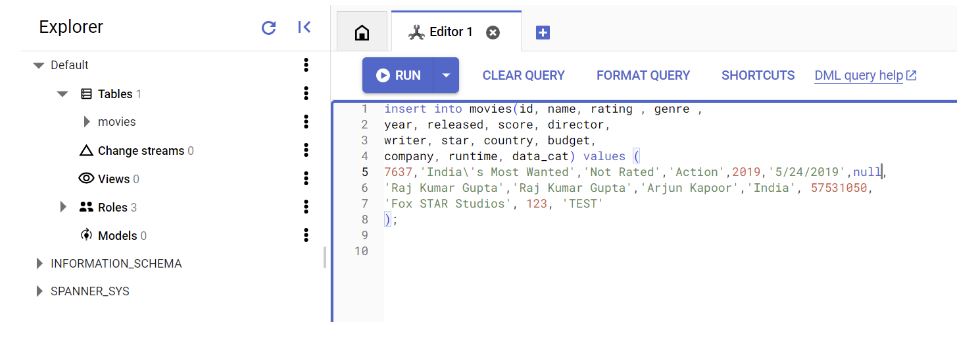
- Open editor tab and RUN the below statement to insert record:
INSERT INTO movies (id, name, rating, genre, year, released, score, director, writer, star, country, budget, company, runtime, data_cat)
VALUES (
7637, ‘India’s Most Wanted’, ‘Not Rated’, ‘Action’, 2019, ‘5/24/2019’, null, ‘Raj Kumar Gupta’, ‘Raj Kumar Gupta’, ‘Arjun Kapoor’, ‘India’, 57531050, ‘Fox STAR Studios’, 123, ‘TEST’
);
Step 5: Register the Vertex AI AutoML model
- You should have already created the classification / regression model and deployed it in the Vertex AI endpoint (as mentioned in the prerequisites section).
- If you haven’t already created the classification model for predicting the movie success rating, refer to the codelab in the “prerequisites” section to create the model
- Now that the model is created, let’s register it in Spanner so you can make it available for your applications. Run the following statement from the editor tab:
CREATE OR REPLACE MODEL movies_score_model
REMOTE OPTIONS (endpoint = ‘https://us-central1-aiplatform.googleapis.com/v1/projects/<your_project_id>/locations/us-central1/endpoints/<your_model_endpoint_id>’);
Replace <your_project_id> and <your_model_endpoint_id> with values from your deployed Vertex AI model endpoint. You should see your model creation step completed in a few seconds.
- Note that the schema structure of your table and the model should match. In this case I have already taken care of this while creating the table by making sure the fields and types in the DDL match the schema of the model dataset in Vertex AI. Take a look at the “Step 3: Create a table” section in this blog for the DDL. You can verify this against the schema structure of the model dataset in Vertex AI by navigating to the “Datasets” section in Vertex AI console and clicking on the ANALYZE tab of the model you are using as seen in the image below:

Step 6: Make Predictions
- All that is left to do now is to use the model we just registered in Spanner to predict the movie user score for the test movie data we inserted into the movies table.
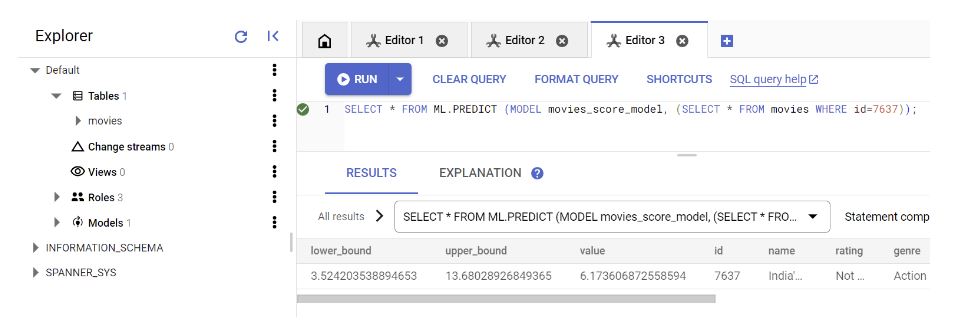
- Run the below query:
SELECT * FROM ML.PREDICT (MODEL movies_score_model, (SELECT * FROM movies WHERE id=7637)); - ML.PREDICT is the method Spanner uses to predict the target value for the input data. This method takes 2 arguments — model name and input data for prediction.
- The subquery “select * from movies where data_cat = ‘TEST’” in our case fetches the test data we have inserted into the movies table for prediction.
That’s it. You should see the prediction result in the field “value” for your test data as shown in the image:
Step 7: Update prediction results to Spanner table
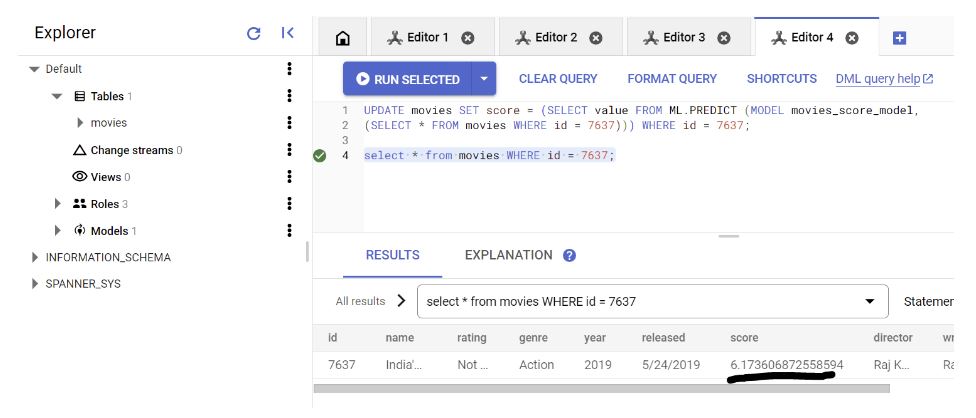
You can choose to write the result of prediction directly to the table, this will be useful particularly when your application requires real time target update. Run the below query for updating the result while predicting:
UPDATE movies SET score = (SELECT value FROM ML.PREDICT (MODEL movies_score_model, (SELECT * FROM movies WHERE id = 7637))) WHERE id = 7637;
Once this is executed, you should see the predicted score updated in your table.
Conclusion
Making ML predictions from Google Cloud Spanner is a powerful way to integrate predictive analytics with your database. By leveraging the capabilities of Vertex AI and the flexibility of Spanner, you can enhance decision-making in real-time applications. This example with movie user score prediction illustrates the potential of combining cloud services to drive data-driven insights. Learn more about the machine learning capabilities of Spanner here.