
Earlier this year we announced Gemma, an open weights model family built to enable developers to rapidly experiment with, adapt, and productionize on Google Cloud. Gemma models can run on your laptop, workstation, or on Google Cloud through either Vertex AI or Google Kubernetes Engine (GKE) using your choice of Cloud GPUs or Cloud TPUs. This includes training, fine-tuning, and inference using PyTorch and JAX, leveraging vLLM, HuggingFace TGI, and TensorRT LLM on Cloud GPUs as well as JetStream and Hugging Face TGI (Optimum-TPU) on Cloud TPUs.
Our benchmarks indicate up to 3X training efficiency (better performance per dollar) for Gemma models using Cloud TPU v5e when compared to our baseline of Llama-2 training performance. Earlier this week, we released JetStream, a new cost-efficient and high-performance inference engine. We analyzed Gemma inference performance on Cloud TPU and found 3X inference efficiency gain (more inferences per dollar) for LLM inference when serving Gemma on JetStream compared to the prior TPU inference stack that we used as the baseline.
In this post, we review the training and inference performance of Gemma models on Google Cloud accelerators. The results we present are snapshots in time as of April 2024. We anticipate that the infrastructure efficiency and quality of these models will continue to evolve and improve through the contributions of the open-source community, our enterprise users, and the teams at Google.
Background: Gemma model architecture details
The Gemma family of models include two variants, Gemma 2B and Gemma 7B (dense decoder architecture). We pre-trained Gemma with 2 trillion and 6 trillion tokens for the 2B and 7B models, respectively, with the context length of 8,192 tokens. Both models use a head dimension of 256, and both variants utilize Rotary Positional Embeddings (RoPE).
While the Gemma 7B model leverages a multihead attention mechanism, Gemma 2B utilizes multi-query attention. This approach aids in reducing memory bandwidth requirements during the inference process, which can potentially be advantageous for Gemma 2B on-device inference scenarios, where memory bandwidth is often limited.
Gemma training performance
To assess the training infrastructure for a given model or a category of similarly sized models, there are two important dimensions: 1) effective model flops utilization; and 2) relative performance per dollar.
Effective model flops utilization
Model FLOPs Utilization (MFU) is the ratio of the model throughput, i.e., the actual floating-point operations per second performed by the model relative to the peak throughput of the underlying training infrastructure. We use the analytical estimate for the number of floating-point operations per training step and the step-time to compute the model throughput (ref. PaLM). When applied to mixed-precision training settings (Int8), the resultant metric is called Effective Model FLOPs Utilization (EMFU). All else being equal, a higher (E)MFU indicates improved performance per unit cost. Improvements in MFU directly translate to cost savings for training.
Gemma training setup
Pre-training for Gemma models was done internally at Google using TPU v5e. It employed two v5e-256 for Gemma 2B and 16 Cloud TPU v5e-256 for Gemma 7B.
We measured the (E)MFU for Gemma models on Cloud TPU. We present the performance on both Cloud TPU v5e and Cloud TPU v5p since both are the latest Cloud TPU generations (at the time of writing this post). Cloud TPU v5e is the most cost-efficient TPU to date on a performance per dollar basis. By contrast, Cloud TPU v5p, is the most powerful and scalable TPU available for more complex LLM architectures, such as mixture of experts and alternative workloads such as large ranking and recommendation systems.
The following graph presents the EMFU for the Gemma 2B and Gemma 7B training run with bf16 precision and mixed precision (int8) training (using AQT).

Gemma-2b & 7b Effective Model Flops Utilization. Measured using MaxText on TPU v5e-256 and v5p-128. context length 8192. As of Feb, 2024.
These results were derived using the MaxText reference implementation. We also provide an implementation for training and fine-tuning Gemma models using Hugging Face Transformers.
Achieving high-performance training with MaxText
We recognize that comparing training infrastructure performance across model types is a difficult problem, due to differences in model architectures, training parameters such as context length and the difference in the scale of underlying cluster. We selected Llama 2 published results (total number of tokens and GPU hours) as a baseline for comparison with Gemma 7B training for the following reason:
-
Similarity of model architecture with respect to Gemma 7B
-
Gemma 7B was trained with 2X context length, and therefore the comparison favors Llama 2 baseline

Gemma-7b and baseline relative training performance per dollar. Measured using Gemma 7B (MaxText) on TPU v5e-256 and v5p-128. context length 8192. Baseline (LLama2-7b) performance is derived using total GPU hours and total number of training tokens as per the published results. Performance/$ is derived using the list price of respective accelerators. As of Feb, 2024.
We derived performance per dollar using (peak-flops*EMFU)/ (list price of VM instance). Using the MaxText reference implementation, we observed up to 3X better performance per dollar for the Gemma 7B model with respect to the baseline training performance (Llama2 7B). Please note that the performance or performance-per-dollar differences presented here are functions of the model architecture, hyperparameters, the underlying accelerator and training software; better performance results cannot be solely attributed to any of these factors alone.
Gemma inference performance
LLM inference is often memory-bound, while training can benefit from massive parallelism. Inference comprises two phases, each with different computational characteristics: prefill and decode. The prefill phase can operate in the compute-bound regime (if num tokens > peak flops / HBM bandwidth), while the decode phase is auto-regressive and tends to be memory-bound unless batched efficiently. Since we are processing one token at a time in the decode phase, the batch size to escape the memory-bound region tends to be higher. Therefore, simply increasing overall batch size (for both prefill and decode) may not be optimal. Because of throughput and latency, along with prefix- and decode-length interplay, we treat input (prefill) and output (decode) numbers separately, and focus on output tokens below.
Next, to describe our observations, we use throughput-per-dollar as a metric as it represents the number of output tokens per second that a model server can generate across all requests from users. This is the Y-axis in the graphs measured in million output tokens. This number is further divided by compute engine CUD pricing for a specific region for Cloud TPU v5e.
Improved cost-efficiency for TPU inference with JetStream on Cloud TPU v5e
Measuring inference performance is challenging because throughput, cost, and latency can be impacted by a number of factors, such as the size of the model, accelerator type, kind of model architecture, precision format used, etc. We therefore used cost efficiency (cost per million tokens) as the metric to measure performance of JetStream as compared to the baseline TPU inference stack. We observed up to 3X gain in cost-efficiency, as depicted in the chart below (lower is better), with the optimized JetStream stack for TPU inference as compared to the baseline TPU inference stack.
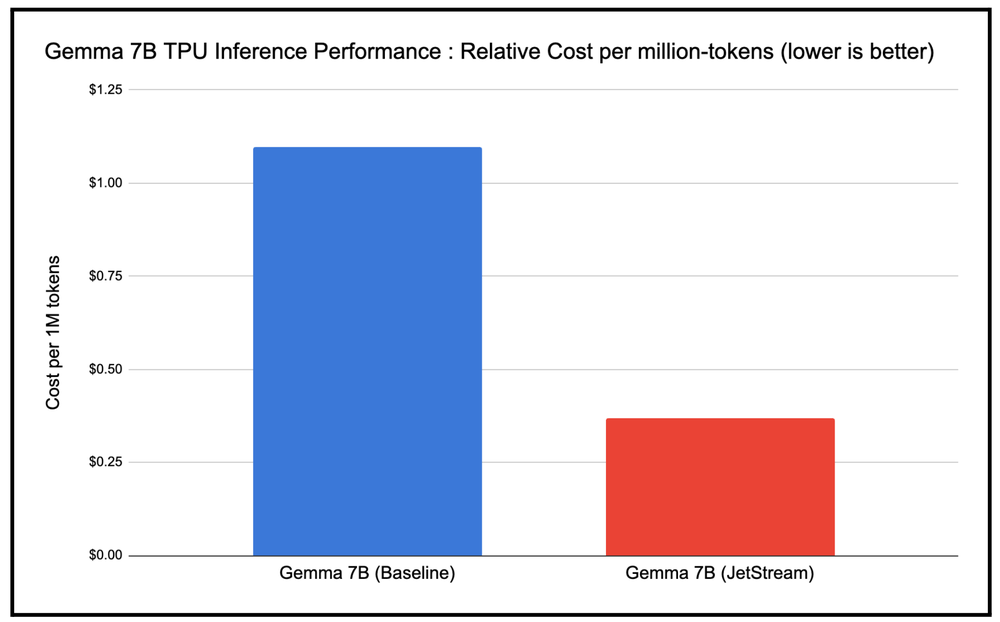
JetStream cost per 1M token as compared to baseline TPU inference stack. Google internal data. Measured using Gemma 7B (MaxText) on TPU v5e-8. Input length 1024, output length 1024 for a specific request rate and batch size. Continuous batching, int8 quantization for weights, activations, KV cache. As of April, 2024.
Serving at scale, high-throughput per dollar for Gemma 7B with JetStream TPU Inference
We also wanted to observe the performance of serving Gemma 7B at scale using the JetStream stack and compare it with the baseline TPU inference stack. As part of this experiment, we varied the request rate sent to these TPU inference stacks from 1 to 256 requests per second, then measured the throughput per dollar for serving Gemma 7B with variable-length input and output tokens. We observe a consistent behavior that throughput-per-dollar for serving Gemma 7B on JetStream is higher than the baseline, even for higher request rates.
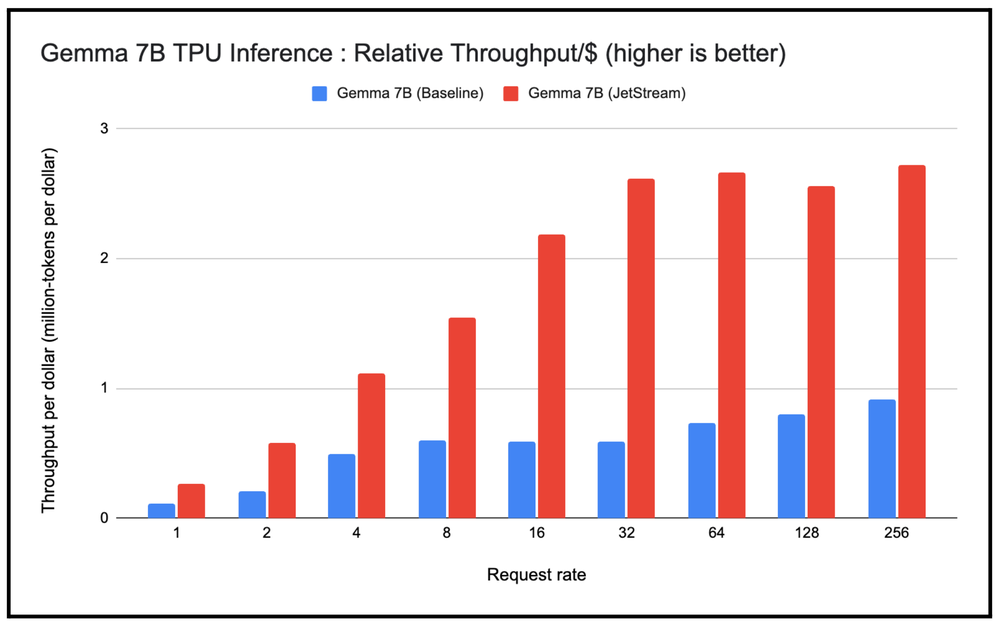
JetStream throughput per dollar (million-tokens per dollar) as compared to baseline TPU inference stack. Google internal data. Measured using Gemma 7B (MaxText) on TPU v5e-8. Input length 1024, output length 1024 for varying request rate from 1 to 256. Continuous batching, int8 quantization for weights, activations, KV cache. As of April, 2024.
Measuring throughput per dollar and cost per million tokens
We orchestrated the experiments using the JetStream container on Google Kubernetes Engine (GKE). The input dataset contains variable-length inputs and outputs and therefore mimics the real-world language model input traffic. To generate the graph, we deployed the Gemma models with JetStream and gradually increased the requests per second to the model endpoint. Increasing the request rate initially translates to higher batch size, higher throughput, and also increased per token latency. But once a critical batch size is reached, further requests are queued, giving rise to the plateau in throughput in terms of number of output tokens generated.
We recognize that the benchmark presented above is sensitive to prompt-length distribution, sampling, and batching optimizations, and can be further improved using variations of high-performance attention kernels and other adaptations. If you want to try out the benchmarks, AI on GKE benchmarking framework enables you to run automated benchmarks on GKE for AI workloads.
High-performance LLM inference on Google Cloud
For large-scale, cost-efficient serving for LLMs, Google Cloud offers a wide range of options that users can adopt based on their orchestration, framework, serving layer, and accelerator preferences. These options include GKE as an orchestration layer, which supports both Cloud TPUs and GPUs for large model inference. Furthermore, each of the accelerators offer a range of serving-layer options, including JetStream (JAX, PyTorch, MaxText), Hugging Face TGI, TensorRT-LLM, and vLLM.
Summary
Regardless of whether you prefer JAX or PyTorch as your framework, self-managed flexibility with GKE orchestration or a fully-managed unified AI platform (Vertex AI), Google Cloud provides AI-optimized infrastructure to simplify running Gemma at scale and in production, using either Cloud GPUs or TPUs. Google Cloud offers a comprehensive set of high-performance and cost-efficient training, fine-tuning and serving options for Gemma models — or any other open-source or custom large language models.
Based on training performance for Gemma models using Cloud TPU v5e and v5p, we observed that using the Gemma reference implementation for training with MaxText delivers up to 3X more performance per dollar compared to the baseline. We also observed that using JetStream for Inference on Cloud TPU delivers up to 3X better inference efficiency gains as compared to the baseline. Whether you are interested in running your inference on Cloud GPUs or TPUs, there are highly optimized serving implementations for Gemma models.
To get started, please visit the Gemma documentation for an overview of Gemma models, the model access, on device variants of Gemma and all the resources. You can also read the Gemma technical report to learn more about its models, architecture, evaluation and safety benchmarks. Finally, visit the Gemma on GKE documentation for easy-to-follow recipes to start experimenting. We can’t wait to see what you build with Gemma.