At Ninja Van, running applications in a stable, scalable environment is business-critical. We are a fast-growing tech-enabled express logistics business with operations across South East Asia. In the past 12 months, we’ve partnered with close to two million businesses to deliver around two million parcels daily to customers, with the help of more than 40,000 workers and employees.
We are an established customer of Google Cloud, and continue to work closely with them to expand into new products and markets, including supply chain management and last mile courier services.
Deploying a secure, stable, container platform
To run the applications and microservices architecture that enable our core businesses, we opted to deploy a secure and stable container platform. We had been early adopters of containerization. We were initially running our container workload in CoreOS with a custom scheduler, Fleet. As we monitor the activities in the open source community, it was evident Kubernetes was gaining more traction and is becoming more and more popular. We decided to run our own Kubernetes cluster and API server, later deploying a number of Compute Engine virtual machines, consisting of both control plane and worker nodes.
As we dived deeper into Kubernetes, we realized that a lot of what we did was already baked into its core functionalities, such as service discovery. This feature enables applications and microservices to communicate with each other without the need to know where the container is deployed to among the worker nodes. We felt that if we continued maintaining our discovery system, we would just be reinventing the wheel. Thus, we dropped what we had in favor of this Kubernetes core feature.
We also found the opportunity to engage with and contribute to the open source community working on Kubernetes compelling. With Kubernetes being open standards-based, we gained the freedom and flexibility to adapt our technology stack to our needs.
However, we found upgrading a self-managed Kubernetes challenging and troublesome in the early days and decided to move to a fully managed Kubernetes service. Among other benefits, we could upgrade Kubernetes easily through Google Kubernetes Engine (GKE) user interface or Google Cloud command line tool. We could also enable auto upgrades simply by specifying an appropriate release channel.
Simplifying the operation of multiple GKE clusters
With a technology stack based on open-source technologies, we have simplified the operation of multiple clusters in GKE. For monitoring and logging operations, we have moved to a centralized architecture to colocate the technology stack on a single management GKE cluster. We use Elasticsearch, Fluentbit and Kibana for logging and Thanos, Prometheus and Grafana for monitoring. When we first started, logging and monitoring were distributed across individual clusters, which meant that administrators had to access the clusters separately which led to a lot of operational inefficiencies. This also meant maintaining duplicated charts across different instances of Kibana and Grafana.
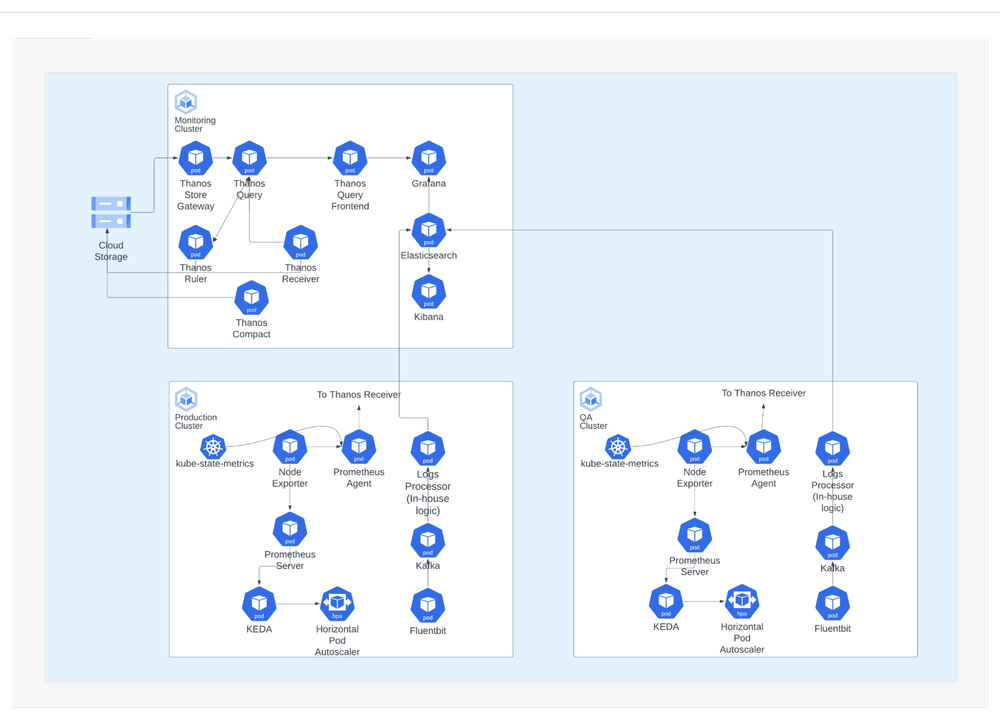
For CI/CD, we run a dedicated DevOps GKE cluster used for hosting developer toolsets and running the pipelines. We embrace the Atlassian suite of services, such as JIRA, Confluence, Bitbucket, Bamboo to name a few. These applications are hosted in the same DevOps GKE cluster.
Our CI/CD is centralized, but custom steps can be put in, giving some autonomy to teams. When a team pushes out new versions of codes, our CI pipeline undertakes the test and build processes. This then produces container image artifacts for backend services and minified artifacts for frontend websites. Typically, the pipelines are parameterized to push out and test the codes in development and testing environments, and subsequently deploy them into sandbox and production. Depending on their requirements, application teams have the flexibility to opt for a fully automated pipeline or a semi-automated one, that requires manual approval for deployment to production.
Autoscaling also comes into play during runtime. As more requests come in, we need to scale up to more containers, but shrink down automatically as the number of requests decreases. To support autoscaling based on our metrics, we integrate KEDA to our technology stack.
Delivering a seamless development experience
In a sense, our developers are our customers as well as our colleagues. We aim to provide a frictionless experience for them by automating the testing, deployment, management and operation of application services and infrastructure. By doing this, we allow them to focus on building the application they’re assigned.
To do this, we’re using DevOps pipelines to automate and simplify infrastructure provisioning and software testing and release cycles. Teams can also self-serve and spin up GKE clusters with the latest environment builds mirroring production with non-production sample data preloaded, which gives them a realistic environment to test the latest fixes and releases.
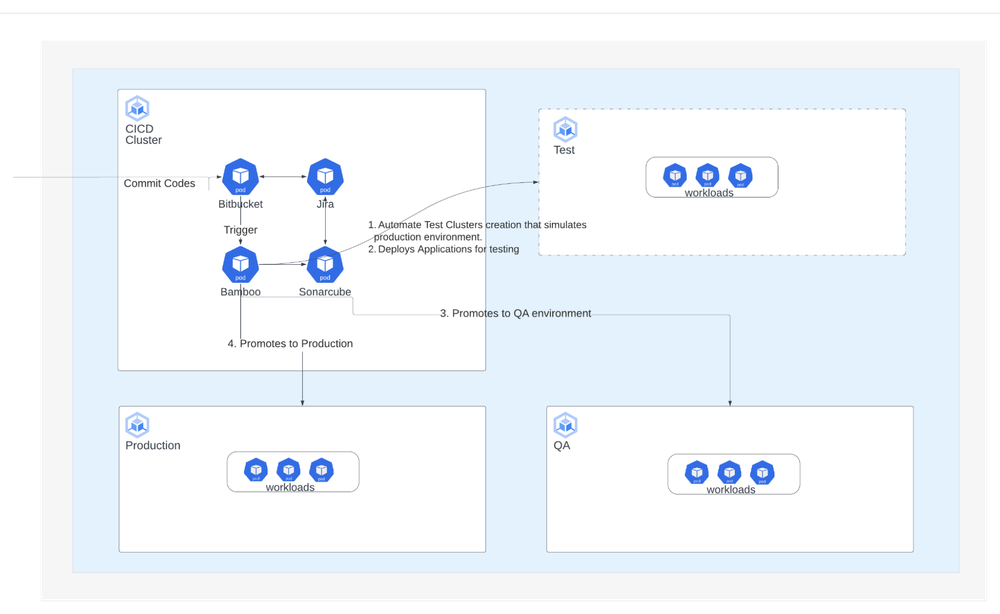
As a build proceeds to deployment, they can visit a Bamboo CI/CD Console to track progress.
Code quality is critical to our development process. An engineering excellence sub-vertical within our business monitors code quality through part of our CI/CD using the SonarQube open-source code inspection tool. We set stringent unit test coverage percentage requirements and do not allow anything into our environment that fails unit or integration testing.
We release almost once a day excluding code freezes on days like Black Friday or Cyber Monday, when we only release bug fixes or features that need to be deployed urgently during demand peaks. While we’ve not changed our release schedule with GKE, we’ve been able to undertake concurrent builds in parallel environments, enabling us to effectively manage releases across our 200-microservice architecture.
Latency key to Google Cloud and GKE selection
When we moved from other cloud providers to Google Cloud and GKE, the extremely low latency between Google Cloud data centers, in combination with reliability, scalability and competitive pricing, gave us confidence Google Cloud was the right choice. In a scenario with a lot of people using the website, we can provide a fast response time and a better customer experience.
In addition, Google Cloud makes the patching and upgrading of multiple GKE clusters a breeze by automating the upgrade process and proactively informing us when an automated upgrade or change threatens to break one of our APIs.
Google Cloud and GKE also open up a range of technical opportunities for our business, including simplification. Many of our services use persistent storage, and GKE provides a simple way to automatically deploy and manage them through their Container Storage Interface (CSI) driver. The CSI driver enables native volume snapshots and in conjunction with Kubernetes CronJob, where we can easily take automated backups of the disks running services such as TiDB, MySQL, Elasticsearch and Kafka. On the development front, we are also exploring Skaffold, which opens up possibilities for development teams to improve their inner development loop cycle and develop more effectively as if their local running instance is deployed within a Kubernetes cluster.
Overall, the ease of management of GKE means we can manage our 200-microservice architecture in 15 clusters with just 10 engineers even as the business continues to grow.
If you want to try this out yourself, check out a hands-on tutorial where you will set up a continuous delivery pipeline in GKE that automatically rebuilds, retests, and redeploys changes to a sample application.