
About three years ago, JCB, one of the biggest Japanese payment companies, launched a project to develop new high-value services with agility. We set up a policy of starting small from scratch without using the existing system, which we call the concept of “Dejima”, where we focused on improving various aspects such as team structure, risk management, and application and platform development process.
Until now, large Japanese enterprises have built decision-making systems focused on eliminating unnecessary business processes and efficiently increasing quarterly profits. As a result, we are seeing more organizational structures that make it difficult to take on new challenges or experiments with trial and error. We wanted to breathe a new life into this situation, and that is how the concept of Dejima came up. In the Edo period, Japan closed its national border to other countries under its national isolation policy. At the time, Dejima was the only area where special rules were applied and allowed people from different cultures to come and go, and trade. This special rule generated the culture of inclusion and led to Dejima’s prosperity. Like Dejima, we believe that creating an organization that is independent from other business practices can be effective in enabling digital transformation for the organization.
We have been able to make this transformation with the direct help of the Google Cloud and its products such as Google Kubernetes Engine (GKE), Cloud Spanner and Anthos Service Mesh, applying domain-driven design and microservice architecture. We named this the “JCB Digital Enablement Platform (JDEP),” which now hosts multiple business critical production services.
A key benefit of GKE is that the team can easily add resources and release them when they are finished, allowing them to be flexible to accommodate busy periods and off-seasons. Meanwhile, Anthos Service Mesh helps us manage complex environments easily. With containerization and managed services, we are prepared for the future for when more services go into production, as it would be easy to maintain and provide version upgrade support. At the same time, Cloud Spanner ensures that we maintain a 99.99% availability at all times.
Our initial motivation for introducing SRE practices was to break proverbial walls between business, development and operations, which was a success. Now we are focused on ensuring its reliability and maintaining customer satisfaction with our SRE practices.
To ensure the success of SRE practices that we implemented, there were a few categories we needed to address, from defining the organizational culture and practices to ensuring the policies attached to the new models created were practical enough to be implemented on the ground level. This is so that the Dejima concept remains sustainable for the long run.
Instilling a culture of measurement
Here, “appropriate” reliability is the key. According to the conventional way of thinking at JCB, “service failure must not occur” and “SLA should be maintained as high as possible.” We started by discussing what was the “appropriate reliability” that our customers really needed, but it was not as easy as we thought because the level of reliability for user satisfaction differed from application to application.
Eventually, the business, development and operations teams formulated specific SLIs and SLOs together, something we would never have been able to do if we discussed separately. This is because the business is required to compromise on lower service levels, since our reliability standard used to be too high. The collaboration of development and operations teams is necessary to understand how our system works upon our users’ interactions.
After Google Cloud helped us run a series of workshops where all teams participated, we saw change within the organization. The business team started evangelizing SRE to other members in the business department, and the development and operations teams started collaborating autonomously. We felt like we were working at Google speed, accomplishing so much in a short amount of time.
Understanding SRE as an entire company is necessary to progress. We are now working on creating internal training materials to spread the SRE concept throughout the company.
Eliminating ambiguity
With the cooperation of Google Cloud, we have created a Team Charter that defines the team’s mission, values and engagement models. We also created policy documents that include Incident Response Policy, Postmortem Policy, On-call Policy, Toil Policy and Error Budget Policy, to eliminate ambiguity in day-to-day operations.
For example, when an incident occurs, we can identify exactly the level of importance, the roles that are assigned to each person, and in what order they need to follow. When to do a postmortem, who owns it? What to do if the error budget is exhausted? How do other teams reach out to SRE when they have problems? The written policy documents will dramatically improve efficiency and motivate teams to adopt a culture of learning from failures.
The format for such policies are written in Google’s SRE book, but when we adopt it, it needs to take into account the circumstances specific to our company. Simply copying an existing policy won’t work, which is why it’s important to formulate a policy that fits the situation each team is in.
Reformalizing teams
Based on these policies, JCB’s SRE team has two sub-teams. One is called Sheriff which works as the platform SRE, and provides infrastructure services for the application team. The other is called the Diplomat which works as the embedded SRE, and participates in the application team to lead productionisation. There is also a team called Architecture that is separate from the SRE teams whose role is to consult SRE on system design and review architecture.
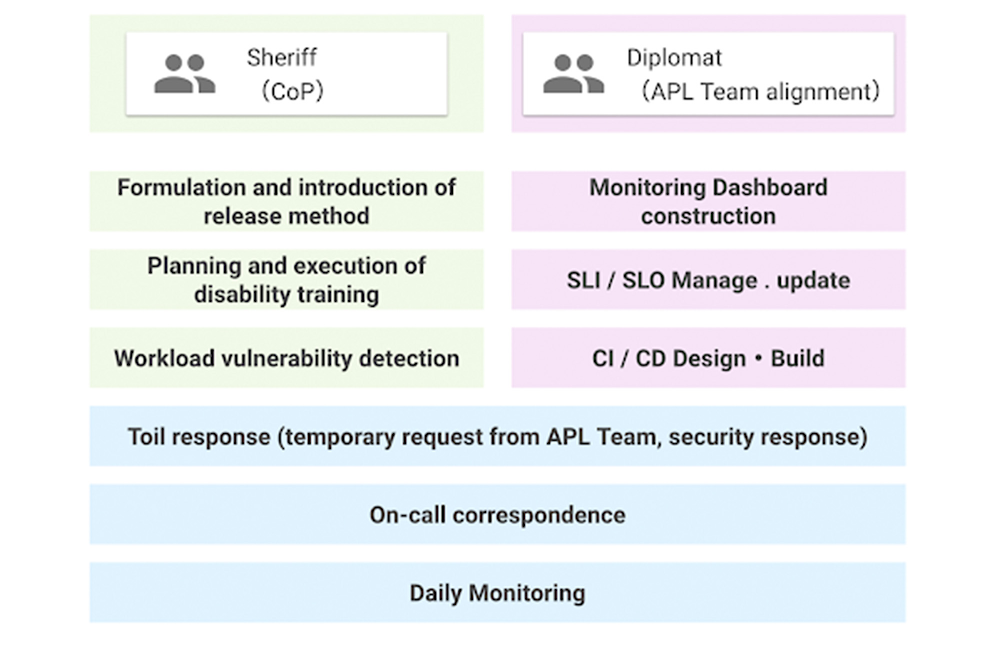
The SRE team was a single role when it was first launched, but now has two sub-teams. This is because as the number of application teams increases, the number of support tasks for the teams also increases, which can result in a shortage of resources to work on overall improvement. Securing people who are not interrupted from day-to-day support tasks and focusing on the main task improves efficiency.
Whereas both sub-teams share the on-call duty, some engineers are not allowed to do it by contract as they are not allowed to get paged. For those who cannot participate in on-call duties, we created what’s called a Toil Shift, which allows them to focus on resolving tickets in our backlogs instead.
This works well so far, but we will keep evolving as our business grows.