With Vertex AI Model Garden, Google Cloud strives to deliver highly efficient and cost-optimized ML workflow recipes. Currently, it offers a selection of more than 150 first-party, open and third-party foundation models. Last year, we introduced the popular open source LLM serving stack vLLM on GPUs, in Vertex Model Garden. Since then, we have witnessed rapid growth of serving deployment. Today, we are thrilled to introduce Hex-LLM, High-Efficiency LLM Serving with XLA, on TPUs in Vertex AI Model Garden.
Hex-LLM is Vertex AI’s in-house LLM serving framework that is designed and optimized for Google’s Cloud TPU hardware, which is available as part of AI Hypercomputer. Hex-LLM combines state-of-the-art LLM serving technologies, including continuous batching and paged attention, and in-house optimizations that are tailored for XLA/TPU, representing our latest high-efficiency and low-cost LLM serving solution on TPU for open-source models. Hex-LLM is now available in Vertex AI Model Garden via playground, notebook, and one-click deployment. We can’t wait to see how Hex-LLM and Cloud TPUs can help your LLM serving workflows.
Design and benchmarks
Hex-LLM is inspired by a number of successful open-source projects, including vLLM and FlashAttention, and incorporates the latest LLM serving technologies and in-house optimizations that are tailored for XLA/TPU.
The key optimizations in Hex-LLM include:
-
The token-based continuous batching algorithm to ensure the maximal memory utilization for KV caching.
-
A complete rewrite of the PagedAttention kernel that is optimized for XLA/TPU.
-
Flexible and composable data parallelism and tensor parallelism strategies with special weights sharding optimization to run large models efficiently on multiple TPU chips.
In addition, Hex-LLM supports a wide range of popular dense and sparse LLM models, including:
-
Gemma 2B and 7B
-
Gemma 2 9B and 27B
-
Llama 2 7B, 13B, and 70B
-
Llama 3 8B and 70B
-
Mistral 7B and Mixtral 8x7B
As the LLM field keeps evolving, we are also committed to bringing in more advanced technologies and the latest and greatest foundation models to Hex-LLM.
Hex-LLM delivers competitive performance with high throughput and low latency. We conducted benchmark experiments, and the metrics that we measured are explained as following:
-
TPS (tokens per second) is the average number of tokens a LLM server receives per second. Similar to QPS (queries per second), which is used for measuring the traffic of a general server, TPS is for measuring the traffic of a LLM server but in a more fine-grained fashion.
-
Throughput measures how many tokens the server can generate for a certain timespan at a specific TPS. This is a key metric for estimating the capability of processing a number of concurrent requests.
-
Latency measures the average time to generate one output token at a specific TPS. This estimates the end-to-end time spent on the server side for each request, including all queueing and processing time.
Note that there is usually a tradeoff between high throughput and low latency. As TPS increases, both throughput and latency should increase. The throughput will saturate at a certain TPS, while the latency will continue to increase with higher TPS. Thus, given a particular TPS, we can measure a pair of throughput and latency metrics of the server. The resultant throughput-latency plot with respect to different TPS gives an accurate measurement of the LLM server performance.
The data used to benchmark Hex-LLM is sampled from the ShareGPT dataset, which is a widely adopted dataset containing prompts and outputs in variable lengths.
In the following charts, we present the performance of Gemma 7B and Llama 2 70B (int8 weight quantized) models on eight TPU v5e chips:
-
Gemma 7B model: 6ms per output token for the lowest TPS, 6250 output tokens per second at the highest TPS;
-
Llama 2 70B int8 model: 26ms per output token for the lowest TPS, 1510 output tokens per second at the highest TPS.


Get started in Vertex AI Model Garden
We have integrated the Hex-LLM TPU serving container into Vertex AI Model Garden. Users can access this serving technology through the playground, one-click deployment, or Colab Enterprise Notebook examples for a variety of models.
Vertex AI Model Garden’s playground is a pre-deployed Vertex AI Prediction endpoint integrated into the UI. Users type in the prompt text and the optional arguments of the request, click the SUBMIT button, and then get the model response quickly. Try it out with Gemma!

To deploy a custom Vertex Prediction endpoint with Hex-LLM, one-click deployment through the model card UI is the easiest approach:
1. Navigate to the model card page and click on the “DEPLOY” button.
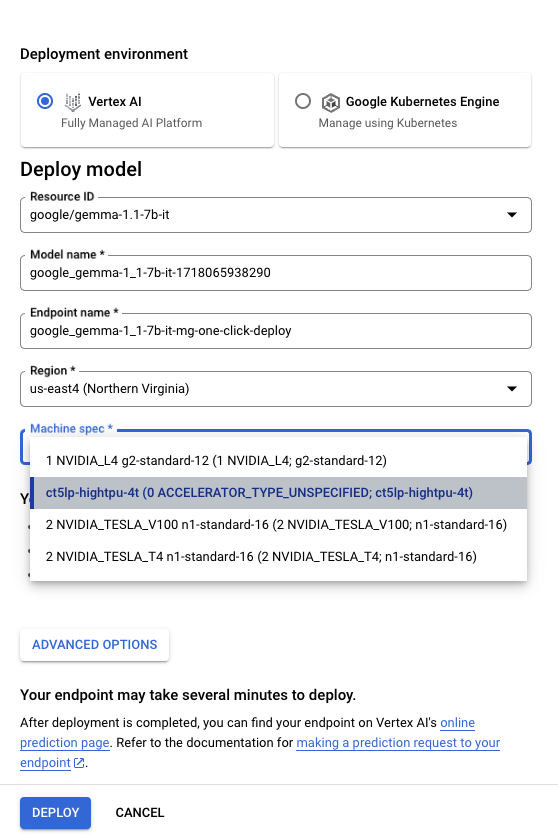
2. For the model variation of interest, select the TPU v5e machine type ct5lp-hightpu-*t for deployment. Click “DEPLOY” at the bottom to begin the deployment process. You can receive two email notifications: one for when the model is uploaded and one for when the endpoint is ready.
For maximum flexibility, users can use Colab Enterprise notebook examples to deploy a Vertex Prediction endpoint with Hex-LLM using the Vertex Python SDK.
1. Navigate to the model card page and click on the “OPEN NOTEBOOK” button.
2. Select the Vertex Serving notebook. This will open the notebook in Colab Enterprise.
3. Run through the notebook to deploy using Hex-LLM and send prediction requests to the endpoint.
The code snippet for the deployment function is as follows.
- code_block
- <ListValue: [StructValue([('code', 'def deploy_model_hexllm(rn model_name: str,rn model_id: str,rn service_account: str,rn machine_type: str = "ct5lp-hightpu-1t",rn tensor_parallel_size: int = 1,rn hbm_utilization_factor: float = 0.6,rn max_running_seqs: int = 256,rn endpoint_id: str = "",rn min_replica_count: int = 1,rn max_replica_count: int = 1,rn) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:rn """Deploys models with Hex-LLM on TPU in Vertex AI."""rn if endpoint_id:rn aip_endpoint_name = (rn f"projects/{PROJECT_ID}/locations/{REGION}/endpoints/{endpoint_id}"rn )rn endpoint = aiplatform.Endpoint(aip_endpoint_name)rn else:rn endpoint = aiplatform.Endpoint.create(display_name=f"{model_name}-endpoint")rnrn hexllm_args = [rn "–host=0.0.0.0",rn "–port=7080",rn "–log_level=INFO",rn "–enable_jit",rn f"–model={model_id}",rn "–load_format=auto",rn f"–tensor_parallel_size={tensor_parallel_size}",rn f"–hbm_utilization_factor={hbm_utilization_factor}",rn f"–max_running_seqs={max_running_seqs}",rn ]rn hexllm_envs = {rn "PJRT_DEVICE": "TPU",rn "RAY_DEDUP_LOGS": "0",rn "RAY_USAGE_STATS_ENABLED": "0",rn "MODEL_ID": model_id,rn "DEPLOY_SOURCE": "notebook",rn }rn if HF_TOKEN:rn hexllm_envs.update({"HF_TOKEN": HF_TOKEN})rnrn model = aiplatform.Model.upload(rn display_name=model_name,rn serving_container_image_uri=HEXLLM_DOCKER_URI,rn serving_container_command=[rn "python", "-m", "hex_llm.server.api_server"rn ],rn serving_container_args=hexllm_args,rn serving_container_ports=[7080],rn serving_container_predict_route="/generate",rn serving_container_health_route="/ping",rn serving_container_environment_variables=hexllm_envs,rn serving_container_shared_memory_size_mb=(16 * 1024), # 16 GBrn serving_container_deployment_timeout=7200,rn )rnrn model.deploy(rn endpoint=endpoint,rn machine_type=machine_type,rn deploy_request_timeout=1800,rn service_account=service_account,rn min_replica_count=min_replica_count,rn max_replica_count=max_replica_count,rn )rn return model, endpoint'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3ee245193dc0>)])]>
Here, users can customize the deployment to best align with their needs. For instance, they can deploy with multiple replicas to handle a large amount of projected traffic.
Take the next step
To learn more about how Vertex AI can help your organization, click here, and to learn more about how Google Cloud customers are innovating with generative AI, read How 7 businesses are putting Google Cloud’s AI innovations to work.