
Who is supposed to manage generative AI applications? While AI-related ownership often lands with data teams, we’re seeing requirements specific to generative AI applications that have distinct differences from those of a data and AI team, and at times more similarities with a DevOps team. This blog post explores these similarities and differences, and considers the need for a new ‘GenOps’ team to cater for the unique characteristics of generative AI applications.
In contrast to data science which is about creating models from data, Generative AI relates to creating AI enabled services from models and is concerned with the integration of pre-existing data, models and APIs. When viewed this way, Generative AI can feel similar to a traditional microservices environment: multiple discrete, decoupled and interoperable services consumed via APIs. And if there are similarities with the landscape, then it is logical that they share common operational requirements. So what practices can we take from the world of microservices and DevOps and bring to the new world of GenOps?
What are we operationalising? The AI agent vs the microservice
How do the operational requirements of a generative AI application differ from other applications? With traditional applications, the unit of operationalisation is the microservice. A discrete, functional unit of code, packaged up into a container and deployed into a container-native runtime such as kubernetes. For generative AI applications, the comparative unit is the generative AI agent: also a discrete, functional unit of code defined to handle a specific task, but with some additional constituent components that make it more than ‘just’ a microservice and add in its key differentiating behavior of being non-deterministic in terms of both its processing and its output:
-
Reasoning loop – The control logic defining what the agent does and how it works. It often includes iterative logic or thought chains to break down an initial task into a series of model-powered steps that work towards the completion of a task.
-
Model definitions – One or a set of defined access patterns for communicating with models, readable and usable by the Reasoning Loop
-
Tool definitions – a set of defined access patterns for other services external to the agent, such as other agents, data access (RAG) flows, and external APIs. These should be shared across agents, exposed through APIs and hence a Tool definition will take the form of a machine-readable standard such as an OpenAPI specification.
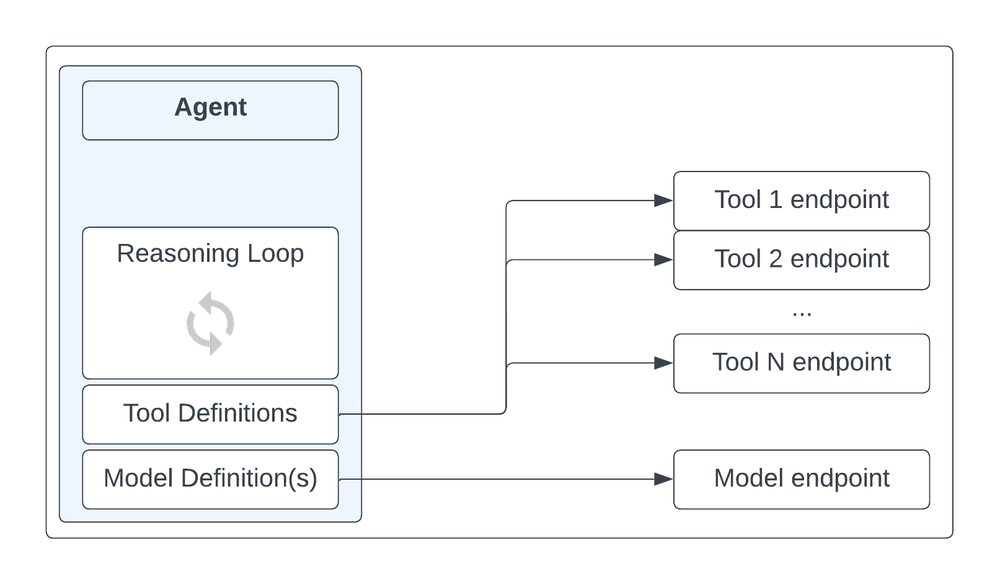
Logical components of a generative AI agent
The Reasoning Loop is essentially the full scope of a microservice, and the model and Tool definitions are its additional powers that make it into something more. Importantly, although the Reasoning Loop logic is just code and therefore deterministic in nature, it is driven by the responses from non-deterministic AI models, and this non-deterministic nature is what provides the need for the Tool, as the agent ‘chooses for itself’ which external service should be used to fulfill a task. A fully deterministic microservice has no need for this ‘cookbook’ of Tools for it to select from: Its calls to external services are pre-determined and hard coded into the Reasoning Loop.
However there are still many similarities. Just like a microservice, an agent:
-
Is a discrete unit of function that should be shared across multiple apps/users/teams in a multi-tenancy pattern
-
Has a lot of flexibility with development approaches, a wide range of software languages are available to use, and any one agent can be built in a different way to another.
-
Has very low inter-dependency from one agent to another: development lifecycles are decoupled with independent CI/CD pipelines for each. The upgrade of one agent should not affect another agent.
Operational platforms and separation of responsibilities
Another important difference is service-discovery. This is a solved-problem in the world of microservices where the impracticalities for microservices to track the availability, whereabouts and networking considerations for communicating with each other were taken out of the microservice itself and handled by packaging the microservices into containers and deploying these into a common platform layer of kubernetes and Istio. With Generative AI agents, this consolidation onto a standard deployment unit has not yet happened. There are a range of ways to build and deploy a generative AI agent, from code-first DIY approaches through to no-code managed agent builder environments. I am not against these tools in principle, however they are creating a more heterogeneous deployment landscape than what we have today with microservices applications and I expect this will create future operational complexities.
To deal with this, at least for now, we need to move away from the Point-to-Point model seen in microservices and adopt a Hub-and-Spoke model, where the discoverability of agents, Tools and models is done via the publication of APIs onto an API Gateway that provides a consistent abstraction layer above this inconsistent landscape.
This brings the additional benefit of clear separation of responsibilities between the apps and agents built by development teams, and Generative AI specific components such as models and Tools:
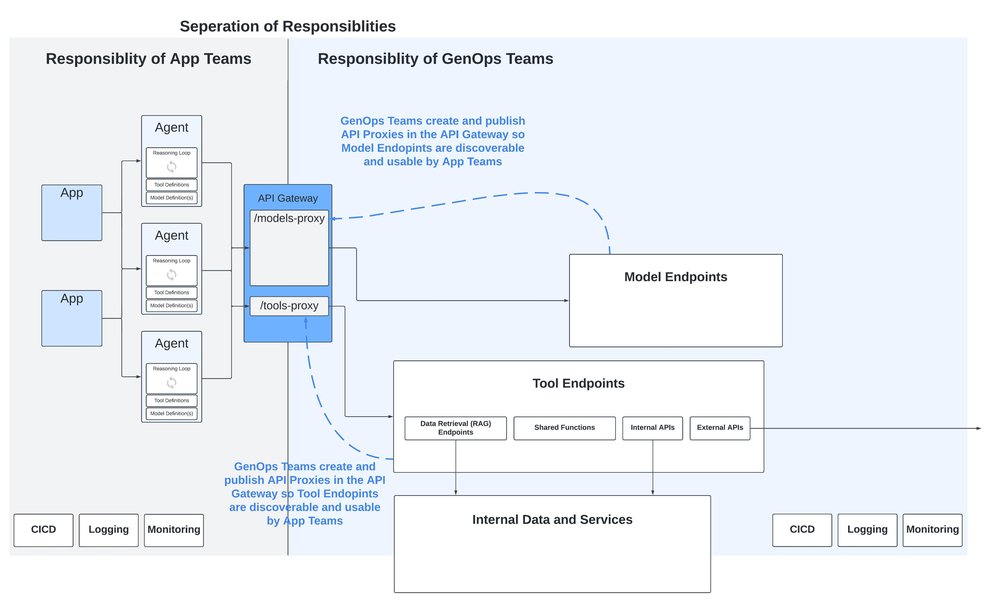
Separating responsibilities with an API Gateway
All operational platforms should create a clear point of separation between the roles and responsibilities of app and microservice development teams from the responsibilities of the operational teams. With microservice based applications, responsibilities are handed over at the point of deployment, and focus switches to non-functional requirements such as reliability, scalability, infrastructure efficiency, networking and security.
Many of these requirements are still just as important for a generative AI app, and I believe there are some additional considerations specific to generative agents and apps which require specific operational tooling:
1. Model compliance and approval controls
There are a lot of models out there. Some are open-source, some are licensed. Some provide intellectual property indemnity, some do not. All have specific and complex usage terms that have large potential ramifications but take time and the right skillset to fully understand.
It’s not reasonable or appropriate to expect our developers to have the time or knowledge to factor in these considerations during model selection. Instead, an organization should have a separate model review and approval process to determine whether usage terms are acceptable for further use, owned by legal and compliance teams, supported on a technical level by clear, governable and auditable approval/denial processes that cascade down into development environments.
2. Prompt version management
Prompts need to be optimized for each model. Do we want our app teams focusing on prompt optimization, or on building great apps? Prompt management is a non-functional component and should be taken out of the app source code and managed centrally where they can be optimized, periodically evaluated, and reused across apps and agents.
3. Model (and prompt) evaluation
Just like an MLOps platform, there is clearly a need for ongoing assessments of model response quality to enable a data-driven approach to evaluating and selecting the most optimal models for a particular use-case. The key difference with Gen AI models being the assessment is inherently more qualitative compared to the quantitative analysis of skew or drift detection of a traditional ML model.
Subjective, qualitative assessments performed by humans are clearly not scalable, and introduce inconsistency when performed by multiple people. Instead, we need consistent automated pipelines powered by AI evaluators, which although imperfect, will provide consistency in the assessments and a baseline to compare models against each other.
4. Model security gateway
The single most common operational feature I hear large enterprises investing time into is a security proxy for safety checks before passing a prompt on to a model (as well as the reverse: a check against the generated response before passing back to the client).
Common considerations:
-
Prompt Injection attacks and other threats captured by OWASP Top 10 for LLMs
-
Harmful / unethical prompts
-
Customer PII or other data requiring redaction prior to sending on to the model and other downstream systems
Some models have built in security controls; however this creates inconsistency and increased complexity. Instead a model agnostic security endpoint abstracted above all models is required to create consistency and allow for easier model switching.
5. Centralized Tool management
Finally, the Tools available to the agent should be abstracted out from the agent to allow for reuse and centralized governance. This is the right separation of responsibilities especially when involving data retrieval patterns where access to data needs to be controlled.
RAG patterns have the potential to become numerous and complex, as well as in practice not being particularly robust or well maintained with the potential of causing significant technical debt, so central control is important to keep data access patterns as clean and visible as possible.
Outside of these specific considerations, a prerequisite already discussed is the need for the API Gateway itself to create consistency and abstraction above these Generative AI specific services. When used to their fullest, API Gateways can act as much more than simply an API Endpoint but can be a coordination and packaging point for a series of interim API calls and logic, security features and usage monitoring.
For example, a published API for sending a request to a model can be the starting point for a multi-step process:
-
Retrieving and ‘hydrating’ the optimal prompt template for that use case and model
-
Running security checks through the model safety service
-
Sending the request to the model
-
Persisting prompt, response and other information for use in operational processes such as model and prompt evaluation pipelines.

Key components of a GenOps platform
Making GenOps a reality with Google Cloud
For each of the considerations above, Google Cloud provides unique and differentiating managed services offerings to support with evaluating, deploying, securing and upgrading Generative AI applications and agents:
- Model compliance and approval controls – Google Cloud’s Model Garden is the central model library for over 150 of Google first-party models, partner models, or open source models, with thousands more available via the direct integration with Hugging Face.
- Model security – The newly announced Model Armor, expected to be in preview in Q3, enables inspection, routing and protection of foundation model prompts and responses. It can help with mitigating risks such as prompt injections, jailbreaks, toxic content and sensitive data leakage.
- Prompt version management – Upcoming prompt management capabilities were announced at Google Cloud Next ‘24 that include centralized version controlling, templating, branching and sharing of prompts. We also showcased AI prompt assistance capabilities to critique and automatically re-write prompts.
- Model (and prompt) evaluation – Google Cloud’s model evaluation services provide automatic evaluations for a wide range of metrics prompts and responses enabling extensible evaluation patterns such as evaluating the responses from two models for a given input, or the responses from two different prompts for the same model.
- Centralized Tool management – A comprehensive suite of managed services are available supporting Tool creation. A few to call out are the Document AI Layout Parser for intelligent document chunking, the multimodal embeddings API, Vertex AI Vector Search, and I specifically want to highlight Vertex AI Search: a fully managed, end-to-end OOTB RAG service, handling all the complexities from parsing and chunking documents, to creating and storing embeddings.
As for the API Gateway, Google Cloud’s Apigee allows for publishing and exposure of models and Tools as API Proxies which can encompass multiple downstream API calls, as well as include conditional logic, reties, and tooling for security, usage monitoring and cross charging.
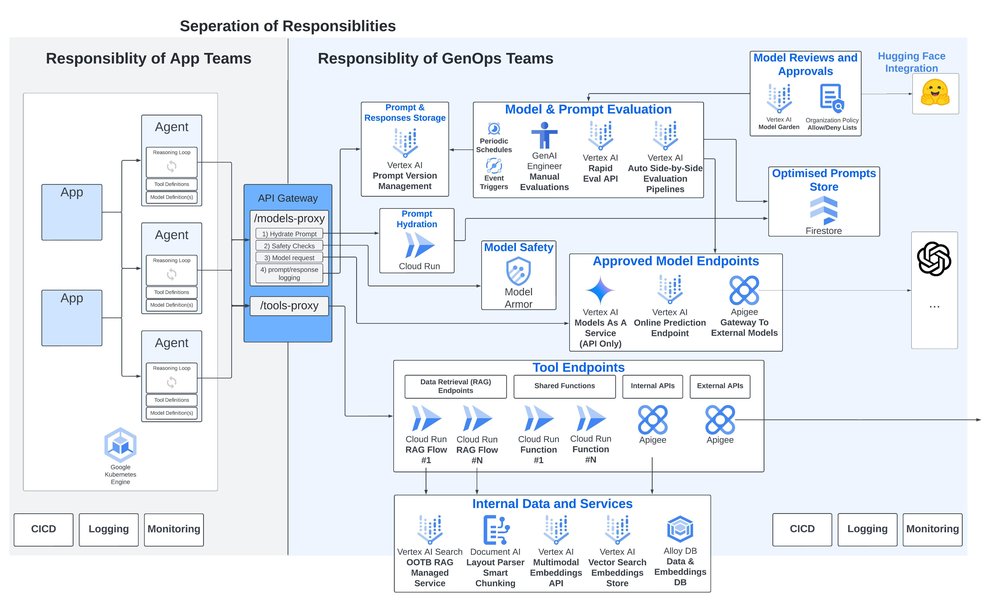
GenOps with Google Cloud
Regardless of size, for any organization to be successful with generative AI, they will need to ensure their generative AI application’s unique characteristics and requirements are well managed, and hence an operational platform engineered to cater for these characteristics and requirements is clearly required. I hope the points discussed in this blog make for helpful consideration as we all navigate through this exciting and highly impactful new era of technology.
If you are interested in learning more, reach out to your Google Cloud account team if you have one, or feel free to contact me directly.