
A United States grocery store chain wanted to leverage data from various areas of their business to enhance operations and generate additional revenue. The company faced several challenges, including disparate legacy systems, data quality concerns, and a lack of cloud expertise.
To address these challenges, the company collaborated with Pythian and Google Cloud to design a secure, scalable, and flexible Enterprise Data Platform (EDP) on Google Cloud. The EDP enabled the company to:
- Improve operational efficiency through near real-time demand modeling.
- Increase online sales through better product recommendations.
- Generate additional revenue by selling anonymized data (expected to have more than 30% margins, doubling their annual revenue)
The EDP was designed to meet the company’s specific security, privacy, and scalability requirements and incorporated data segmentation, role-based access control, and comprehensive metadata tracking.
To attain the customer’s objectives, in collaboration with Google Cloud, Pythian designed an Enterprise Data Platform that meets modern analytics demands: the EDP is self-service, clean and integrates data of many types, Further, it has the ability to scale while ensuring strong security controls and data governance.
Designing a data platform for the enterprise
The design of a secure enterprise-scale data platform requires several key capabilities:
Security from the start
The data platform must always be secure, from its initial ingestion to its delivery to end users. This includes having secure processes in place to audit the platform and detect potential breaches.
Programmatic configuration management using automation
Programmatic configuration management tracks and monitors changes to a software system’s configuration metadata, frequently used along version control and CI/CD pipelines. It is used to build robust and stable systems through automated management and monitoring of configuration data updates.
Managed services whenever possible
Google Cloud managed services are a great option for businesses as creating a comparable solution can be difficult and require resources that are beyond the reach of most IT teams.
Design for scalability
Cloud-based data platforms should have a modular architecture that scales independently and in real-time based on demand. This ensures scalability as the platform matures while minimizing run costs and enabling experimentation.
A data ingestion layer that’s compatible with multiple formats
A highly secure data ingestion layer processes diverse file formats from various data sources (e.g., Oracle, Non-Oracle, SQL, and No-SQL). It acts as a monitored landing zone, allowing raw data to be processed by suitable Google Cloud or third-party tools.
Once landed and initially processed, the data is standardized into Avro/Parquet format, simplifying subsequent processing logic. The data ingestion layer supports database log-based CDC or batch processing, crucial for modernizing an enterprise data warehouse.
Data processing with disparate engines
Different data use cases often have unique processing requirements that may not align with a single big data processing engine. Google Cloud offers a diverse range of big data processing tools, including Dataproc, Dataflow, and Dataform, among others.
To meet specific job requirements, a data platform needs to be flexible enough to execute processes in the most suitable environment. For instance, a data conversion task to Avro format for machine learning purposes may utilize Spark due to its robust Pandas Dataframes libraries. On the other hand, a streaming process could leverage Dataflow for its development simplicity, while data that’s in BigQuery can benefit from using Dataform for native SQL pipelines like aggregations or KPI calculations. Lastly, you may need fast queries for large data sets where you’d leverage Apache Iceberg Tables accessed directly from BigQuery as an external BigLake table.
By adopting an open and flexible data platform, customers gain the freedom to select the processing engine, source data formats, and target system based on their workload. This empowers them to fully leverage the extensive capabilities of Google Cloud, both presently and in the future.
Data segmentation
Data segmentation involves grouping data based on use cases, information types, data sensitivity, and required access levels. Once segmented, different security parameters and authentication rules are established for each data segment.
Data lineage
Data lineage traces the flow of data from source to destination, capturing transformations like data cleaning, aggregations, and calculations. A robust data lineage process includes a business glossary (e.g., Looker’s LookML models) to define columns, involvement of data owners for accurate data representation, and an automated lineage gathering process to avoid pipeline gaps.
Data lineage can be a challenging area to implement in an enterprise context, and holistic coverage isn’t always possible. Instead focus on key lineage flows and increment across the platform rather than aiming for perfection from day one. For further guidance on data lineage, please refer to this guide or reach out to a skilled data lineage partner such as Pythian.
Role-based access control
Role-based access control (RBAC) provides a mechanism to configure precise and granular permissions, dictating user or group interactions with objects in your environment. Within an EDP, RBAC enables data storage in a centralized location like a data lake, while maintaining fine-grained access controls tailored to user requirements.
Decoupled compute and storage
Separating storage and compute is essential for building a scalable and cost-effective data platform. In most cloud pricing models, storage costs less than compute. As enterprise data volumes grow exponentially, it becomes impractical to store data long-term in compute-bound storage systems like HDFS.
By decoupling storage from compute, you can take advantage of object storage, which offers affordable, virtually unlimited, and scalable storage that is inherently highly available.
Built-in AI/ML capabilities
AI/ML can be used to automate tasks, improve data quality, and generate insights from data.
BigQuery ML lets you create and run ML models by using GoogleSQL queries. BigQuery also integrates with Vertex AI for online model serving and MLOps capabilities. Duet AI, an AI-powered collaborator in Google Cloud, complements BigQuery by helping you generate, complete, or even explain an SQL query.
Complete metadata tracking
Metadata tracking lets you track data about the data in the data platform. Metadata is critical to the long term support of a data platform, as it often is the only window into how a given pipeline is currently running or has previously performed. Metadata is used heavily by a DataOps team to track, alert, and respond to issues quickly and often automatically.
Pythian’s EDP for Google Cloud couples a modern, integrated, cloud-native analytics platform based on BigQuery with the professional services required to customize it to your needs. As in the referenced use case, Pythian can use your data sources to transform your data into insights using modern business intelligence (BI) tools like Looker or Tableau.
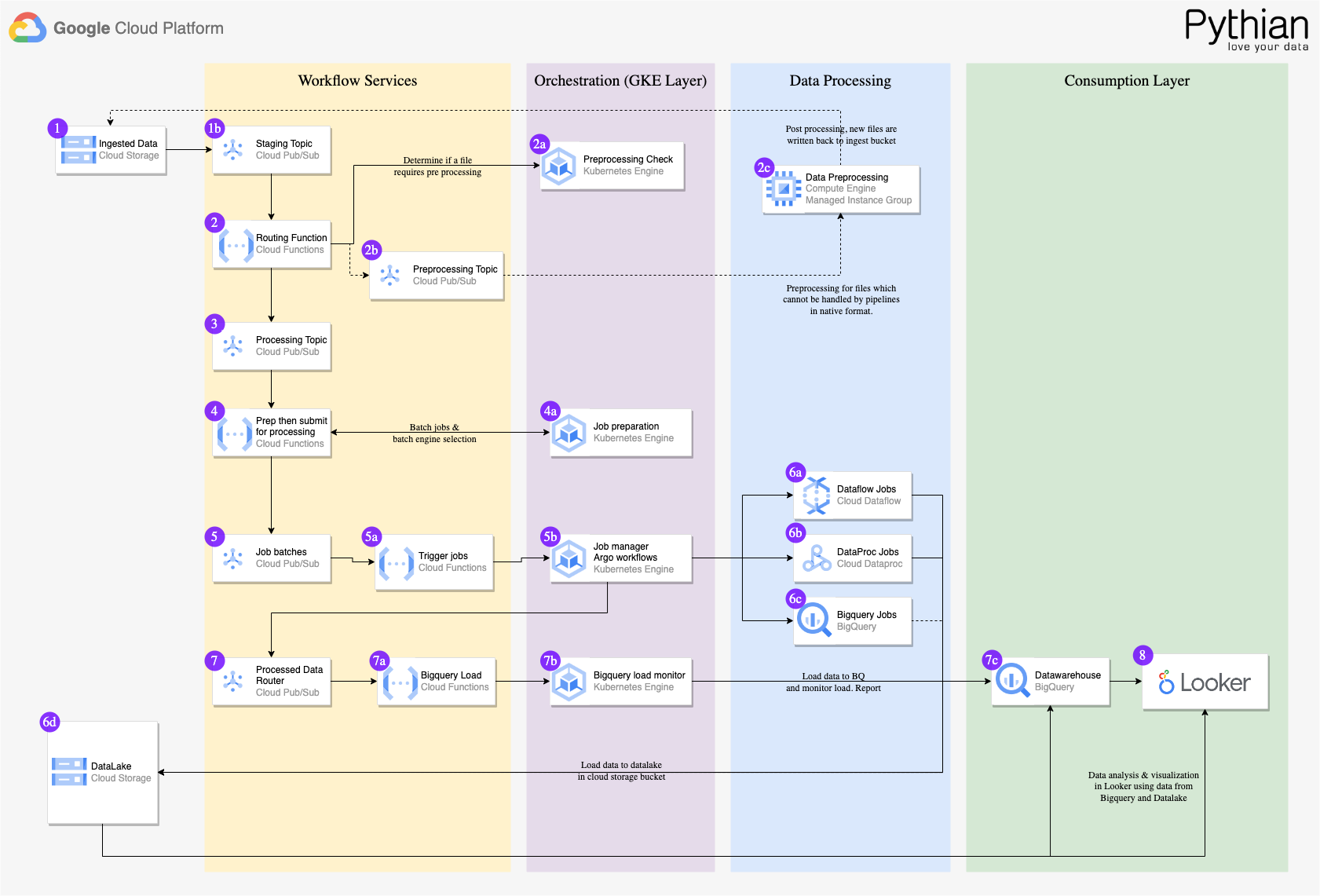
Pythian EDP components
- Cloud Storage – Object storage for companies of all sizes.
- Pub/Sub– Used as a message queue and for processing control throughout the data platform to provide resilience in the event a compute processor is unavailable.
- Cloud Functions– Within the EDP, Cloud Functions is used to manage all orchestration logic such as finding the next task in a queue.
- Composer– Manage task dependencies and process retries. Composer enables Pythian to architect pipeline jobs that can run in any Airflow environment.
- Data loss prevention API – To allow for sensitive data to be obfuscated when needed.
- Dataproc Serverless – Used to ingest, clean, and transform the initial raw source data. Spark was chosen due to the wide variety of files and processes which can be integrated with it.
- Dataflow – The main processing engine for all non-BigQuery processes after data is ingested. Allows for code-free deployments and updates as requirements change.
- Dataform/ dbt – Used to generate SQL native pipelines for data manipulation directly within BigQuery.
- BigQuery – Using BigQuery and GCS, Pythian implements a Lakehouse and Data Mesh architecture for its customers.
- BigQuery Studio – Provides a comprehensive set of features for data ingestion, preparation, analysis, exploration, and visualization to perform all data-related tasks in a single environment.
- Looker – Users can analyze, visualize, and act on insights from the data. As part of Pythian’s EDP solution, you can have prebuilt Looker dashboards deployed out-of-the-box with the option to implement custom dashboards specific to your use case.
Results
The EDP delivered immediate value, as the customerimplemented their main use case within eight weeks, validating the architecture’s readiness.
The EDP’s metadata processing pattern enabled rapid development and deployment of pipelines, allowing business analysts to take ownership and reducing reliance on IT support.
Performance testing demonstrated the EDP’s efficiency, processing 250GB of data with over 2 billion rows in just 30 minutes, boosting confidence for future implementations.
A data platform within reach
Establishing the foundations of a secure, scalable and cost-effective data platform to meet the needs of your enterprise is within your grasp and can be accelerated to weeks, rather than in months or years that such initiatives traditionally take.
Using Pythian’s EDP Quickstart assets, which have been battle-tested and designed around industry-recognized best-practices, you can quickly have a platform set up to unlock the rich value in your data and scale across your enterprise, leveraging data to unlock insights, predictions and products.
Using Google Cloud combined with a skilled services partner like Pythian, you can remove the barriers that sit between your organization and your data to realize tangible and measurable value. Google brings data and software together for businesses of all sizes looking to build a data cloud to take your company beyond anything you can imagine today.
To learn more about Pythian and how you can kick start your data platform journey with Pythian Enterprise Data Platform Quickstart for Google Cloud, please see this offering overview and reach out to Pythian to get started.