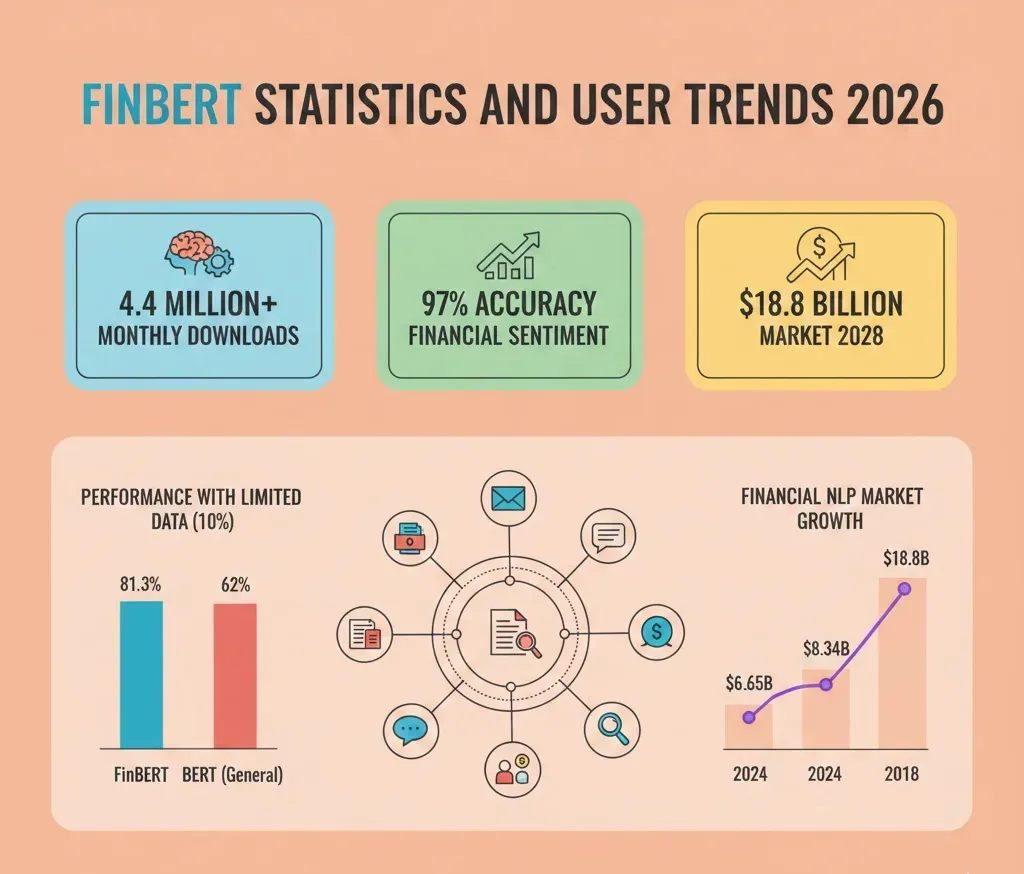
FinBERT recorded 4.4 million combined monthly downloads across all variants in 2026, marking its position as the dominant pre-trained language model for financial sentiment analysis. The model achieved 97% accuracy on benchmark datasets with full annotator agreement, representing a six percentage point improvement over previous state-of-the-art models. Originally developed by Prosus AI and enhanced by HKUST researchers, FinBERT leverages BERT’s transformer architecture fine-tuned on 4.9 billion financial tokens.
FinBERT Key Statistics
- FinBERT variants generated 4.4 million monthly downloads across Hugging Face platform as of 2026
- The model achieved 97% accuracy on Financial PhraseBank sentences with full annotator agreement
- FinBERT training corpus contains 4.9 billion tokens from corporate reports, earnings calls, and analyst reports
- Financial NLP market reached $8.34 billion in 2025 with 25.5% compound annual growth rate
- FinBERT maintained 81.3% accuracy with only 10% training data versus 62% for general BERT
FinBERT Download Statistics by Variant
The Hugging Face platform provides real-time metrics on FinBERT model usage across specialized variants. ProsusAI’s original sentiment model leads adoption with 2.3 million monthly downloads.
The yiyanghkust/finbert-tone variant recorded 2.1 million monthly downloads for financial tone analysis applications. Specialized variants for ESG classification and forward-looking statement detection serve compliance and sustainability analysis requirements.
| FinBERT Variant | Monthly Downloads | Primary Function |
|---|---|---|
| ProsusAI/finbert | 2,321,534 | Financial Sentiment Analysis |
| yiyanghkust/finbert-tone | 2,074,803 | Financial Tone Analysis |
| yiyanghkust/finbert-esg | 49,823 | ESG Classification |
| yiyanghkust/finbert-fls | 2,759 | Forward-Looking Statement Detection |
FinBERT Training Corpus and Model Architecture
FinBERT’s domain expertise stems from pre-training on extensive financial communication corpora. The model processed 2.5 billion tokens from corporate reports filed with the SEC EDGAR database.
Earnings call transcripts contributed 1.3 billion tokens from public company filings. The Thomson Investext Database provided 1.1 billion tokens from analyst reports, bringing total training data to 4.9 billion tokens.
| Training Component | Volume | Source |
|---|---|---|
| Corporate Reports (10-K & 10-Q) | 2.5 Billion Tokens | SEC EDGAR Database |
| Earnings Call Transcripts | 1.3 Billion Tokens | Public Company Filings |
| Analyst Reports | 1.1 Billion Tokens | Thomson Investext Database |
FinBERT Sentiment Classification Accuracy Benchmarks
Academic validation studies demonstrate FinBERT’s superior performance compared to traditional machine learning approaches. The model achieved 97% accuracy on sentences with full annotator agreement, compared to 85% for general BERT.
FinBERT recorded 86% accuracy across all data, marking a 15 percentage point improvement over prior state-of-the-art models. LSTM approaches reached 76.3% accuracy, while the previous best model achieved 91%.
| Model/Method | Accuracy (Full Agreement) | Accuracy (All Data) |
|---|---|---|
| FinBERT | 97% | 86% |
| BERT (General) | 85% | 71% |
| LSTM | 76.3% | N/A |
| Previous SOTA (FinSSLX) | 91% | N/A |
FinBERT Performance with Limited Training Data
Financial NLP applications frequently encounter limited labeled data availability. FinBERT demonstrated exceptional resilience when training data was constrained to specialized financial applications.
With only 10% of training data, FinBERT maintained 81.3% accuracy while general BERT dropped to 62%. This 19.3 percentage point advantage demonstrates the model’s pre-trained financial knowledge enabling effective transfer learning with minimal labeled examples.
| Training Sample Size | FinBERT Accuracy | BERT Accuracy |
|---|---|---|
| 100% Training Sample | 88.2% | 85.0% |
| 20% Training Sample | 84.5% | 76.7% |
| 10% Training Sample | 81.3% | 62.0% |
FinBERT Misclassification Patterns
Understanding where FinBERT errors occur provides insight into the model’s decision boundaries. The concentration of errors between positive and neutral classifications accounts for 73% of all misclassifications.
Cautionary statements versus negative outlook confusion represents 22% of errors. The minimal 5% positive-negative confusion rate confirms FinBERT’s reliability for detecting sentiment polarity extremes.
| Misclassification Type | Percentage of Errors | Explanation |
|---|---|---|
Positive  Neutral Neutral |
73% | Subtle distinction between optimism and objectivity |
| Negative Neutral |
22% | Cautionary statements vs negative outlook |
| Positive Negative |
5% | Rare polar opposite confusion |
NLP in Finance Market Growth Projections
The broader market context positions FinBERT as infrastructure technology within a rapidly expanding sector. Financial NLP applications achieved double-digit compound annual growth rates through 2026.
Market valuations reached $8.34 billion in 2025, reflecting institutional investment in NLP infrastructure. The projected growth to $18.8 billion by 2028 represents a 27.6% CAGR, driven by regulatory requirements for automated compliance monitoring.
| Year | Market Size (USD Billion) | CAGR |
|---|---|---|
| 2024 | $6.65 – $6.92 | Baseline Year |
| 2025 | $8.34 – $8.88 | 25.5% – 28.2% |
| 2028 | $18.8 | 27.6% |
| 2032 | $31.5 – $53.79 | 21.4% – 25.06% |
FinBERT vs GPT Models Accuracy Comparison
Recent comparative studies evaluated FinBERT’s performance against general-purpose large language models across diverse financial news sources. FinBERT demonstrated superior accuracy on financial news platforms with market-focused content.
Benzinga showed FinBERT achieving 75.56% accuracy compared to GPT-2’s 68.42%, a 7.14 percentage point advantage. Dow Jones results favored FinBERT with 67.69% accuracy versus 62.31% for GPT-2.
| News Source | FinBERT Accuracy | GPT-2 Accuracy | Performance Leader |
|---|---|---|---|
| Benzinga | 75.56% | 68.42% | FinBERT (+7.14%) |
| Dow Jones | 67.69% | 62.31% | FinBERT (+5.38%) |
| Wall Street Journal | 63.25% | 65.48% | GPT-2 (+2.23%) |
| Barron’s | 61.78% | 64.56% | GPT-2 (+2.78%) |
Banking and Financial Services NLP Adoption
The financial services sector represents the primary deployment vertical for FinBERT and competing NLP solutions. Banking, financial services, and insurance collectively control 21.10% of the global NLP market.
North America recorded 33.30% revenue share as the dominant region. Cloud deployment captured 63.40% market share with 24.95% CAGR projected through 2030.
| Metric | 2024 Value | Growth Trajectory |
|---|---|---|
| BFSI NLP Market Share | 21.10% | Largest Industry Vertical |
| North America Revenue Share | 33.30% | Dominant Region |
| Cloud Deployment Share | 63.40% | 24.95% CAGR to 2030 |
| Large Enterprise Adoption | 57.80% | SME growing at 25.01% CAGR |
FinBERT Application Use Cases
Financial institutions deploy FinBERT across multiple operational areas from trading desks to compliance departments. The model’s three-label classification system enables nuanced assessment of market communications.
Trading algorithms incorporate FinBERT sentiment scores as alpha signals for automated decision-making. Compliance teams utilize specialized variants for regulatory document analysis and forward-looking statement identification.
| Application Area | Primary Use Case | Data Sources Analyzed |
|---|---|---|
| Algorithmic Trading | News-based sentiment signals | Financial news, earnings calls |
| Risk Management | Early warning detection | Analyst reports, SEC filings |
| ESG Compliance | Sustainability disclosure analysis | Annual reports, ESG statements |
| Regulatory Compliance | Forward-looking statement identification | MD&A sections, proxy statements |
FAQs
How many monthly downloads does FinBERT receive?
FinBERT variants recorded 4.4 million combined monthly downloads across the Hugging Face platform as of 2026. The ProsusAI/finbert model leads with 2.3 million downloads, while yiyanghkust/finbert-tone accounts for 2.1 million monthly downloads.
What accuracy does FinBERT achieve on benchmark datasets?
FinBERT achieved 97% accuracy on Financial PhraseBank sentences with full annotator agreement and 86% accuracy across all data. This represents a 15 percentage point improvement over prior state-of-the-art models and a 12 percentage point advantage over general BERT.
How large is FinBERT’s training corpus?
FinBERT was trained on 4.9 billion tokens from financial communications. The corpus includes 2.5 billion tokens from corporate reports, 1.3 billion tokens from earnings call transcripts, and 1.1 billion tokens from analyst reports sourced from SEC EDGAR and Thomson Investext databases.
How does FinBERT perform with limited training data?
FinBERT maintained 81.3% accuracy with only 10% of training data, while general BERT dropped to 62% accuracy. This 19.3 percentage point advantage demonstrates FinBERT’s pre-trained financial knowledge enables effective transfer learning with minimal labeled examples for specialized applications.
What is the projected market size for NLP in finance?
The financial NLP market reached $8.34 billion in 2025 with a 25.5% compound annual growth rate. Projections estimate the market will reach $18.8 billion by 2028, representing a 27.6% CAGR driven by regulatory compliance automation and real-time sentiment analysis.