
Cloud TPUs are purpose-built for training of large language models (LLMs), Vision Transformer based architectures, diffusion-based generative models, and recommendation systems. However, up until now, orchestrating large-scale AI workloads with Cloud TPUs could be a lot of work, requiring manual effort to handle failures, logging, monitoring, and other foundational operations.
To address this challenge, this week, we announced the general availability of Cloud TPUs in Google Kubernetes Engine (GKE), our scalable and fully-managed Kubernetes service. This launch brings much-awaited support for GKE to both Cloud TPU v4 and the latest fifth-generation Cloud TPU v5e. In doing so, we’re empowering AI development productivity by leveraging GKE to manage large-scale AI workload orchestration on Cloud TPUs.
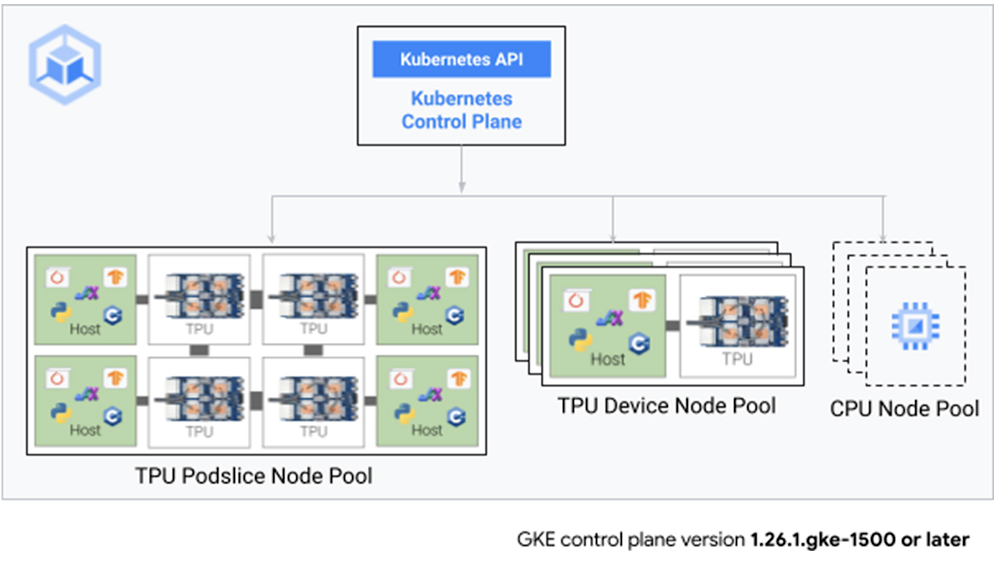
Benefits of Cloud TPUs in GKE
With Cloud TPUs in GKE, we’re bringing together the price-performance of Google’s custom-designed TPUs with the power of GKE. Now you can leverage the simplicity of GKE to express and execute your AI workloads. You can run all types of workloads in a consistent operations environment, taking advantage of GKE features such as auto-scaling, auto-provisioning, auto-repair, and auto-upgrades to ease the burden of day-two operations and manage your resources efficiently. Furthermore, you can combine the power of the TPU and GKE ecosystems, using tools such as Weights & Biases Launch or Google Cloud Managed Service for Prometheus with Cloud TPUs in GKE.
Simplify orchestration with TPU VM node pools in GKE
If your organization already runs web, stateless, stateful, batch, or other workloads on Kubernetes, you’ve experienced the operational benefits of a single platform orchestrating your workloads.
With the general availability of Cloud TPUs in GKE, your AI workloads can now benefit from the consistent orchestration, improved utilization, and multi-tenant capable environment that GKE provides. Cloud TPU node pools can be auto-provisioned and autoscaled to further simplify orchestration and use resources only when you need them. You can consume spot, on-demand, or reserved Cloud TPU instances to use what fits your workload and budget.
Pioneering photo and video creation platform Lightricks is an AI-first company providing an innovative platform for content creators and brands. Lightricks has experienced the operational simplicity of orchestrating their TPUs using GKE:
“TPU in GKE has replaced many of the custom scripts we built to operate our large-model trainings on TPUs.” – Yoav HaCohen, PhD, Core Generative AI Research Team Lead at Lightricks.
Large-scale training using Cloud TPU Multislice in GKE
By enabling horizontal scaling on Cloud TPUs, new Multislice technology lets users train massive AI models more efficiently, by scaling up to tens of thousands of chips in a single training run. Efficient scaling means that you can execute workload almost at the same rate of increase in speed by using a proportional increase in resources.
Furthermore, we also simplify Multislice job abstraction using the newly introduced JobSet API. With the JobSet abstraction, GKE also provides a robust failure-handling mechanism for training jobs that span thousands of TPU chips across hundreds of TPU podslices.
Cost-efficient inference with auto-scaling for TPU VM node pools
Using Kubernetes autoscaler, your TPU node pools makes it easy to scale up your TPU footprint for either inference workloads or interactive development use cases. If your TPU nodes aren’t in use, then the GKE cluster autoscaler removes them, saving you money on what can be costly resources.
Optimize resource sharing and utilization with Kueue
Cloud TPUs in GKE enable novel resource-sharing capabilities, which allow multiple teams in your organization to timeshare TPU resources with queueing capabilities offered by APIs such as Kueue. Your workload still uses the Kubernetes scheduler, but now Kueue allows you to manage these workloads by establishing different priority levels, such that lower priority jobs can use idle resources in between higher priority tasks. This culminates in more optimal TPU resource utilization across multiple teams.
Failure-resilient training and serving with auto-repair
GKE tracks the health of the Cloud TPU VM node pools and initiates repair activities in case one or more TPU nodes become unhealthy. This provides predictable behavior for failure handling for your training and serving workloads. Your workload auto-resumes after any repair event.
Actionable insights from GKE monitoring and logging
You can leverage GKE’s native logging and monitoring features to capture full training or serving logs. If you have GKE system metrics enabled, then Cloud TPU infrastructure metrics such as duty cycle and high-bandwidth memory (HBM) utilization are available in Cloud Monitoring and displayed in the Google Kubernetes Engine section of the Google Cloud console, giving you zero-setup insight into your TPU resource utilization.
Efficient and foundational orchestrator for AI workloads
Support for Cloud TPU VMs in GKE offers a foundational orchestration layer for building your AI/ML infrastructure on Google Cloud. GKE natively offers a powerful suite of tools to operationalize ML models using both TPUs and GPUs. These tools include powerful logging and monitoring, auto-repair and auto-provisioning capabilities.
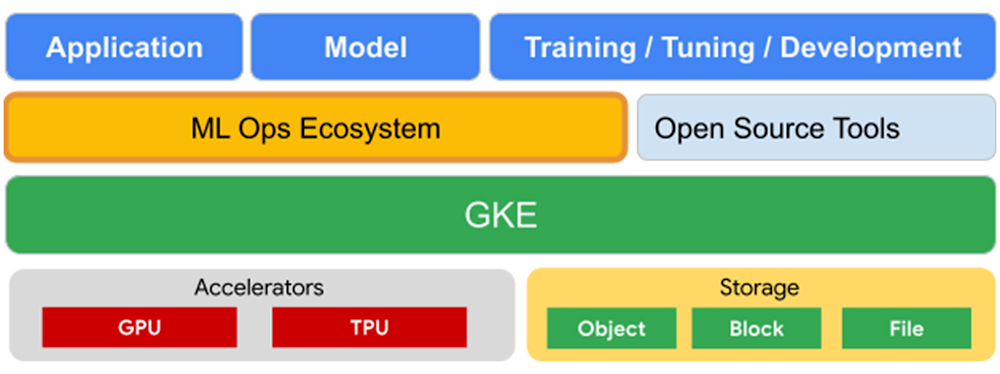
Flexibly orchestrate both Cloud TPUs and GPUs in GKE
With Cloud TPUs in GKE, we are also bringing the added flexibility for customers to build their AI platforms by leveraging the best of both accelerator options in a unified environment.
Our customers are already experiencing these benefits:
“TPU in GKE empowers our ML pipelines by seamlessly integrating TPUs and GPUs, allowing us to leverage the strengths of each for specific tasks and reduce latency and inference costs. For instance, we efficiently process text prompts in batches using a large text encoder on TPU, followed by employing GPUs to run our in-house diffusion model, which utilizes the text embeddings to generate stunning images.”– Yoav HaCohen, PhD – Core Generative AI Research Team Lead, Lightricks
“Anthropic is an AI safety and research company focused on building reliable, interpretable, and steerable AI systems. We’re excited to be working with Google Cloud, with whom we have been collaborating to efficiently train, deploy and share our models. Google Kubernetes Engine (GKE) allows us to run and optimize our GPU and TPU infrastructure at scale, while Vertex AI will enable us to distribute our models to customers via the Vertex AI Model Garden. Google’s next-generation AI infrastructure powered by A3 and TPU v5e will bring price-performance benefits for our workloads as we continue to build the next wave of AI.” – Tom Brown, Co-founder, Anthropic
Next steps
For more details on Cloud TPUs in GKE and to get started, check out the documentation.