In today’s technology landscape, building or modernizing applications demands a clear understanding of your business goals and use cases. This insight is crucial for leveraging emerging tools effectively, especially generative AI foundation models such as large language models (LLMs).
LLMs offer significant competitive advantages, but implementing them successfully hinges on a thorough grasp of your project requirements. A key decision in this process is choosing between a managed LLM solution like Vertex AI and a self-hosted option on a platform such as Google Kubernetes Engine (GKE).
In this blog post, we equip developers, operations specialists, or IT decision-makers to answer the critical questions of “why” and “how” to deploy modern apps for LLM inference. We’ll address the balance between ease of use and customization, helping you optimize your LLM deployment strategy. By the end, you’ll understand how to:
-
deploy a Java app on Cloud Run for efficient LLM inference, showcasing the simplicity and scalability of a serverless architecture.
-
use Google Kubernetes Engine (GKE) as a robust AI infrastructure platform that complements Cloud Run for more complex LLM deployments
Let’s get started!
Why Google Cloud for AI development
But first, what are some of the factors that you need to consider when looking to build, deploy and scale LLM-powered applications? Developing an AI application on Google Cloud can deliver the following benefits:
-
Choice: Decide between managed LLMs or bring your own open-source models to Vertex AI.
-
Flexibility: Deploy on Vertex AI or leverage GKE for a custom infrastructure tailored to your LLM needs.
-
Scalability: Scale your LLM infrastructure as needed to handle increased demand.
-
End-to-end support: Benefit from a comprehensive suite of tools and services that cover the entire LLM lifecycle.
Managed vs. self-hosted models
When weighing the choices for AI development in Google Cloud with your long-term strategic goals, consider factors such as team expertise, budget constraints and your customization requirements. Let’s compare the two options in brief.
Managed solution
Pros:
-
Ease of use with simplified deployment and management
-
Automatic scaling and resource optimization
-
Managed updates and security patches by the service provider
-
Tight integration with other Google Cloud services
-
Built-in compliance and security features
Cons:
-
Limited customization in fine-tuning the infrastructure and deployment environment
-
Potential vendor lock-in
-
Higher costs vs. self-hosted, especially at scale
-
Less control over the underlying infrastructure
-
Possible limitations on model selection
Self-hosted on GKE
Pros:
-
Full control over deployment environment
-
Potential for lower costs at scale
-
Freedom to choose and customize any open-source model
-
Greater portability across cloud providers
-
Fine-grained performance and resource optimization
Cons:
-
Significant DevOps expertise for setup, maintenance and scaling
-
Responsibility for updates and security
-
Manual configuration for scaling and load balancing
-
Additional effort for compliance and security
-
Higher initial setup time and complexity
In short, managed solutions like Vertex AI are ideal for teams for quick deployment with minimal operational overhead, while self-hosted solutions on GKE offer full control and potential cost savings for strong technical teams with specific customization needs. Let’s take a couple of examples.
Build a gen AI app in Java, deploy in Cloud Run
For this blog post, we wrote an application that allows users to retrieve quotes from famous books. The initial functionality was retrieving quotes from a database, however gen AI capabilities offer an expanded feature set, allowing a user to retrieve quotes from a managed or self-hosted large-language model.
The app, including its frontend, are being deployed to Cloud Run, while the models are self-hosted in GKE (leveraging vLLM for model serving) and managed in Vertex AI. The app can also retrieve pre-configured book quotes from a CloudSQL database.

Why is Java a good choice for enterprises building generative AI applications?
-
A mature ecosystem and extensive libraries
-
Scalability and robustness, perfect for handling AI workloads
-
Easy integration with AI models via Spring AI
-
Strong security features
-
Vast Java talent expertise in many organizations
Cloud Run is the easiest and fastest way to get your gen AI apps running in production, allowing a team to:
-
Build fast-scaling, scale-to-zero, API endpoints to serve requests
-
Run your Java gen AI apps in portable containers that are interoperable with GKE
-
Pay only when your code is running
-
Write code that is idiomatic to developers, with high app deployment velocity
Before you start
The Spring Boot Java application supporting this blog post leverages the Spring AI Orchestration Framework. The app is built on Java 21 LTS and Spring Boot and includes build, test, deployment and runtime guidelines to Cloud Run.
Follow the instructions to clone the Git repository and validate that you have Java 21 and GraalVM set up.
The codebase is complemented with reference documentation for building and deploying the app to Cloud Run, respectively deploying and configuring open models to GKE.
Deploy an open model to GKE
Let’s start by deploying an open model LLM to GKE. For this blog post you will deploy the Meta-Llama-3.1-8B-Instruct open model to GKE.
Setting up Hugging Face access and API Token for LLM deployment
To download the LLM during runtime, follow these steps to set up your Hugging Face account and API token:
1. Prerequisites:
-
Ensure you have access to a Google Cloud project with available L4 GPUs and sufficient quota in the selected region.
-
Have a computer terminal with `kubectl` and the Google Cloud SDK installed. You can use the Google Cloud project console’s Cloud Shell, which already has the required tools installed.
2. Hugging Face account and API token:
-
Models, such as Llama 3.1 used here, require a Hugging Face API token to download.
-
Visit Meta’s resource page for Llama models to request access: Meta Llama Downloads. You will need to register an email address to download the files.
-
Go to Hugging Face and create an account using the same email address registered in the Meta access request.
-
Locate the Llama 3 model and fill out the access request form: [Meta Llama 3.1-8B Instruct]. Patiently check for the approval email.
-
Once approved, retrieve your Hugging Face access token from your account profile settings. This access token will be used to authenticate and download the model files during the deployment process.
3. To set up a GKE cluster with the appropriate node pool and GPU configurations for deploying a large language model (LLM) on GCP, follow the steps in the repository. The main steps:
- code_block
- <ListValue: [StructValue([('code', 'gcloud container clusters create $CLUSTER_NAME rn –workload-pool "${PROJECT_ID}.svc.id.goog" rn –location "$REGION" rn –enable-image-streaming –enable-shielded-nodes rn –enable-ip-alias rn –node-locations="$ZONE_1" rn –shielded-secure-boot –shielded-integrity-monitoring rn –workload-pool="${PROJECT_ID}.svc.id.goog" rn –addons GcsFuseCsiDriver rn –num-nodes 1 –min-nodes 1 –max-nodes 5 rn –ephemeral-storage-local-ssd=count=2 rn –enable-ip-aliasrn –no-enable-master-authorized-networks rn –machine-type n2d-standard-4rnrnrngcloud container node-pools create g2-standard-24 –cluster $CLUSTER_NAME rn –accelerator type=nvidia-l4,count=1,gpu-driver-version=latest rn –machine-type g2-standard-8 rn –ephemeral-storage-local-ssd=count=1 rn –num-nodes=1 –min-nodes=0 –max-nodes=2 rn –node-locations $ZONE_1,$ZONE_2 –region $REGION –spot rnrn# for details follow the steps in the repo linked above'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e40cff1aa90>)])]>
You can find open-model LLM deployment and GCLB configurations reference documentation here.
GKE configuration break down
-
Deployment:
-
Creates a single instance of a
vllm-inference-serverpod -
Uses an NVIDIA L4 GPU and allocates specific resources (CPU, memory, ephemeral storage)
-
Mounts empty directories for cache and shared memory
-
Service:
-
Exposes the deployment internally using a ClusterIP
-
Configures the service to be accessible on port 8000
-
BackendConfig:
-
Specifies HTTP health checks for the load balancer, ensuring the service’s health
-
Ingress:
-
Configures an ingress resource to expose the service via Google Cloud Load Balancer (GCLB)
-
Routes external traffic to the
vllm-inference-serverservice on port 8000
vLLM exposes the OpenAI API, in addition to a Native vLLM API. For this blog, we’ll use the API compatible with the OpenAI API specification, as it allows consistency across managed and GKE hosted open models.
With the model and GCLB deployed, notice that the deployment environment variable references two secrets — OpenAPI key and the Hugging face token:
-
The Open API Key in vLLM is defined by you and set using the environment VLLM_API_KEY. It can be any combination of alphanumeric and special characters. You can use Google Cloud Secret Manager to manage this secret.
-
The Hugging Face token is available in the Hugging Face account that you set up eariler.
- code_block
- <ListValue: [StructValue([('code', 'export HF_TOKEN=<paste-your-own-token>rnexport OPENAPI_KEY=<paste-your-own-token>rnkubectl create secret generic huggingface –from-literal="HF_TOKEN=$HF_TOKEN" -n $NAMESPACErnkubectl create secret generic openapikey –from-literal="key=$OPENAPI_KEY" -n $NAMESPACE'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e40cff1a580>)])]>
The alternative? Use a managed model in VertexAI
You can also access a Meta LLama3.1 open model by simply enabling it from the Vertex AI Model Garden as a fully managed Vertex AI service.
You’ll be using the meta/llama3-405b-instruct-maas open model with 405b parameters in the codebase for this blog, available at:
- code_block
- <ListValue: [StructValue([('code', 'REGION=us-central1rnENDPOINT=${REGION}-aiplatform.googleapis.comrnPROJECT_ID="YOUR_PROJECT_ID"rnrnrnLLM_ENDPOINT=https://${ENDPOINT}/v1beta1/projects/${PROJECT_ID}/locations/${REGION}/endpoints/openapi/chat/completions'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e40cff1a700>)])]>
Deploying and configuring the Gen AI Java application to Cloud Run
Validate that you have cloned the code repository and Java 21 is installed [read]:
- code_block
- <ListValue: [StructValue([('code', '# clone repositoryrngit clone https://github.com/GoogleCloudPlatform/serverless-production-readiness-java-gcp.gitrnrn# app available hererncd serverless-production-readiness-java-gcp/ai-patterns/spring-ai-quotes-llm-in-gkernrn# install Java 21 if it is not installed in your env or cloudshellrncurl -s "https://get.sdkman.io" | bashrnsource "$HOME/.sdkman/bin/sdkman-init.sh"rnsdk install java 21.0.4-graal rnrn# Select Y to set as default or usernsdk use java 21.0.4-graalrnrn# validate our Java runtimernjava -versionrnrnrn# observe the outputrnjava version "21.0.4" 2024-07-16 LTSrnJava(TM) SE Runtime Environment Oracle GraalVM 21.0.4+8.1 (build 21.0.4+8-LTS-jvmci-23.1-b41)rnJava HotSpot(TM) 64-Bit Server VM Oracle GraalVM 21.0.4+8.1 (build 21.0.4+8-LTS-jvmci-23.1-b41, mixed mode, sharing)'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e40cff1adc0>)])]>
Set the environment variables you’ll require to connect to your test models:
- code_block
- <ListValue: [StructValue([('code', '# LLM in VertexAI envrnexport VERTEX_AI_PROJECT_ID=<your project id>rnexport VERTEX_AI_LOCATION=us-central1rnexport VERTEX_AI_MODEL=meta/llama3-405b-instruct-maasrnrn# LLM in GKE envrnexport OPENAI_API_KEY=<you API key for the LLM in GKE>rnexport OPENAI_API_GKE_IP=<IP for deployed model>rnexport OPENAI_API_GKE_MODEL=meta-llama/Meta-Llama-3.1-8B-Instructrnrnrnrn# Gemini in VertexAI envrnexport VERTEX_AI_GEMINI_PROJECT_ID=<your project id>rnexport VERTEX_AI_GEMINI_LOCATION=us-central1rnexport VERTEX_AI_GEMINI_MODEL=gemini-1.5-pro-001'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e40cff1aca0>)])]>
Build the app and validate the app in your local environment [read]:
- code_block
- <ListValue: [StructValue([('code', '# Build apprn./mvnw clean package -Pproduction -DskipTestsrnrn# Start the app locallyrnjava -jar target/spring-ai-quotes-llm-in-gke-1.0.0.jarrnrn# Access the app in a browser windowrnhttp://localhost:8083rnrn# Test from a terminalrncurl localhost:8083/random-quote rncurl localhost:8083/random-quote-llmrncurl localhost:8083/random-quote-llmgke'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e40da5dd2e0>)])]>
Build the container image and push the image to Artifact Registry [read]:
- code_block
- <ListValue: [StructValue([('code', '# build container image using cloud-native buildpacksrn./mvnw spring-boot:build-image -DskipTests -Pproduction -Dspring-boot.build-image.imageName=quotes-llmrnrn# tag the imagernexport PROJECT_ID=$(gcloud config list –format 'value(core.project)')rnecho $PROJECT_IDrnrn# The region for the image and deployments are assumed to be us-central1rn# Change them if you wish to use a different regionrnrn# tag and push image to Artifact Registryrngcloud artifacts repositories create quotes-llm rn –repository-format=docker rn –location=us-central1 rn –description="Quote app images accessing LLMs" rn –immutable-tags rn –asyncrngcloud auth configure-docker us-central1-docker.pkg.devrnrndocker tag quotes-llm us-central1-docker.pkg.dev/${PROJECT_ID}/quotes-llm/quotes-llmrndocker push us-central1-docker.pkg.dev/${PROJECT_ID}/quotes-llm/quotes-llm'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e40da5dda60>)])]>
Deploy to Cloud Run and provision the configuration for JVM, Cloud Run and LLM access configuration [read]:
- code_block
- <ListValue: [StructValue([('code', "gcloud run deploy quotes-llm rn –image us-central1-docker.pkg.dev/${PROJECT_ID}/quotes-llm/quotes-llm rn –region us-central1 rn –memory 2Gi –cpu=2 rn –execution-environment gen1 rn –set-env-vars=SERVER_PORT=8080 rn –set-env-vars=JAVA_TOOL_OPTIONS='-XX:+UseG1GC -XX:MaxRAMPercentage=80 -XX:ActiveProcessorCount=2 -XX:+TieredCompilation -XX:TieredStopAtLevel=1 -Xss256k' rn –set-env-vars=VERTEX_AI_GEMINI_PROJECT_ID=${PROJECT_ID} rn –set-env-vars=VERTEX_AI_GEMINI_LOCATION=us-central1 rn –set-env-vars=VERTEX_AI_GEMINI_MODEL=gemini-1.5-pro-001 rn –set-env-vars=VERTEX_AI_PROJECT_ID=${PROJECT_ID} rn –set-env-vars=VERTEX_AI_LOCATION=us-central1 rn –set-env-vars=VERTEX_AI_MODEL=meta/llama3-405b-instruct-maas rnrn –set-env-vars=OPENAI_API_KEY=${OPENAI_API_KEY}rnrn –set-env-vars=OPENAI_API_GKE_IP=${OPENAI_API_GKE_IP} rn –set-env-vars=OPENAI_API_GKE_MODEL=meta-llama/Meta-Llama-3.1-8B-Instruct rn –cpu-boost rn –allow-unauthenticated rnrn# observe the URL, use it for UI or cURL accessrn# example:rn…rnService [quotes-llm] revision [quotes-llm-00008-wq5] has been deployed and is serving 100 percent of traffic.rnService URL: https://quotes-llm-6hr…-uc.a.run.app"), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e40da5dd220>)])]>
Test the application end-to-end
You can now test the application end-to-end as deployed in Cloud Run:
- code_block
- <ListValue: [StructValue([('code', '# Test from a terminalrncurl https://quotes-llm-6hrfwttbsa-uc.a.run.app/random-quote rncurl https://quotes-llm-6hrfwttbsa-uc.a.run.app/random-quote-llmrncurl https://quotes-llm-6hrfwttbsa-uc.a.run.app/random-quote-llmgkernrnrn# Access the app in a browser windowrnhttps://quotes-llm-6hrfwttbsa-uc.a.run.app'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e40da5dda00>)])]>
Here are some model responses:
- code_block
- <ListValue: [StructValue([('code', '# Llama3.1 Model in GKE response: rn{rn "id": 0,rn "quote": "You never really understand a person until you consider things from his point of view… Until you climb inside of his skin and walk around in it.",rn "author": "Harper Lee",rn "book": "To Kill a Mockingbird"rn}rnrnLLama3.1 Model in VertexAI response:rn{rn "id": 0,rn "quote": "The only way to get rid of temptation is to yield to it.",rn "author": "Oscar Wilde",rn "book": "The Picture of Dorian Gray"rn}'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e40da5dd490>)])]>
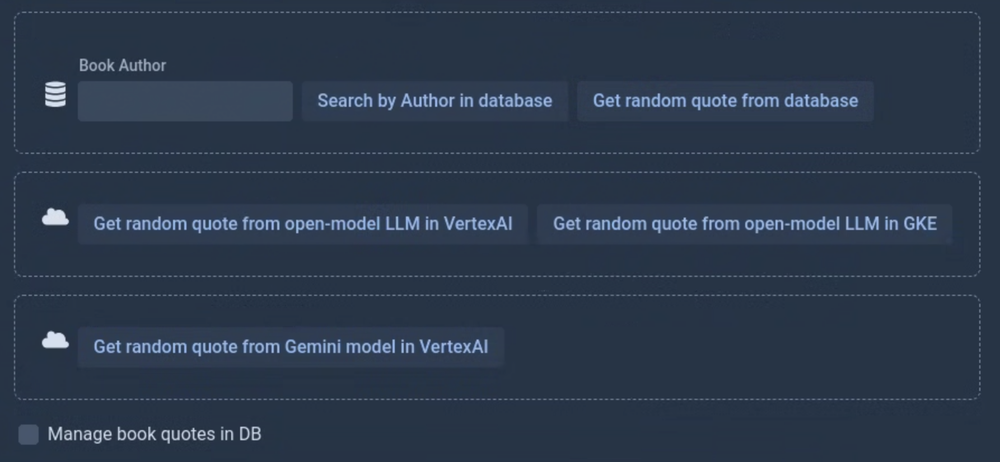
In the App UI you can explore the quotes available in the database, then ask the LLMs to generate quotes for you, using the GKE LLM deployment or in Vertex AI:
Summary
This blog post offers an opinionated guide to Large Language Model (LLM) and Gen AI application deployment on Google Cloud Platform. It emphasizes aligning AI adoption with business needs, comparing managed Vertex AI solutions with self-hosted options on Google Kubernetes Engine (GKE).
The blog post presents:
-
Google Cloud’s advantages for AI development: flexibility, scalability, and comprehensive support
-
Pros and cons of managed vs. self-hosted LLM solutions
-
GKE’s ability to handle complex LLM deployments
-
A production-ready, practical example: a Spring AI Java app deployed to Cloud Run for efficient LLM inference
We hope this post provides you with valuable insights into how to balance ease of use with your customization needs, and gives you the knowledge you need to make informed decisions on LLM deployment strategies.
Let’s not forget that generative AI adoption starts from business needs, not technological aspects!
References
Serving Open Source LLMs on GKE using vLLM framework blog post from our colleague Rick(Rugui) Chen