
SQL is used by approximately 7 million people worldwide to manage and analyze data on a daily basis. Whether you are a data engineer or analyst, how you manage and effectively use your data to provide business driven insights, has become more important than ever.
BigQuery is an industry leading, fully-managed, cloud data warehouse, that helps simplify the end-to-end analytics experience. It starts from data ingestion, preparation, analysis, all the way to ML training and inference using SQL. Today, we are excited to bring new SQL capabilities to BigQuery that extend our support for data quality, security, and flexibility. These new capabilities include:
-
Schema operations for better data quality: create/alter views with column descriptions, flexible column name, LOAD DATA SQL statement
-
Sharing and managing data in a more secure way: authorized stored procedures
-
Analyzing data with more flexibility: LIKE ANY/SOME/ALL, ANY_VALUE (HAVING), index support for arrays & struct
Extending schema support for better data quality
Here’s an overview of how we’ve extended schema support in BigQuery to make it easier for you to work with your data.
Create/alter views with column descriptions (preview)
We hear from customers that they frequently use views to provide data access to others, and the ability to provide detailed information about what is contained in the columns would be very useful. Similar to column descriptions of tables, we’ve extended the same capability for views. Instead of having to rely on Terraform to precreate views and populate column details, you can now directly create and modify column descriptions on views using CREATE/ALTER Views with Column Descriptions statements.
- code_block
- [StructValue([(u’code’, u’– Create a view with column descriptionrnCREATE VIEW view_name (column_name OPTIONS(description= u201ccol xu201d)) ASu2026rnrn– Alter a view with column descriptionrnALTER VIEW view_name ALTER COLUMN column_name rnSET OPTIONS(description=u201ccol xu201d)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ee24784c190>)])]
Flexible column name (preview)
To help you to improve data accessibility and usability, BigQuery now supports more flexibility for naming columns in your preferred international language and using special characters like ampersand (&) and percent sign (%) in the column name. This is especially important for customers with migration needs and international business data. Here is a partial list of the supported special characters:
-
Any letter in any language
-
Any numeric character in any language
-
Any connector punctuation character
-
Any kind of hyphen or dash
-
Any character intended to be combined with another character
-
Example column names:
-
`0col1`
-
`姓名`
-
`int-col`
You can find a full detailed list of the supported characters here.
LOAD DATA SQL statement (GA)
-
“In the past we mainly used the load API to load data into BigQuery, which required engineer expertise to learn about the API and do configurations. Since LOAD DATA was launched, we are now able to load data with SQL only statements, which made it much simpler, more compact and convenient.” – Steven Yampolsky, Director of Data Engineering, Northbeam
Rather than using the load API or the CLI, BigQuery users like the compatibility and convenience of the SQL interface to load data as part of their SQL data pipeline. To make it even easier to load data into BigQuery, we have extended support for a few new use cases:
- Load data with flexible column name (preview)
- code_block
- [StructValue([(u’code’, u’LOAD DATA INTO dataset_name.table_namern(`flexible column name u5217` INT64)rnFROM FILES (uris=[u201cfile_uriu201d], format=u201cCSVu201d);’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ee26d65fc50>)])]
- Load into tables with renamed columns, or columns dropped and added in a short time
- code_block
- [StructValue([(u’code’, u’–Create a table rnCREATE TABLE dataset_name.table_name (col_name_1 INT64);rnrn–Rename a column in the table rnALTER TABLE dataset_name.table_name RENAME COLUMN col_name_1 TO col_name_1_renamed;rnrn–load data into a table with the renamed column rnLOAD DATA INTO dataset_name.table_namern(col_name_1_renamed INT64)rnFROM FILES (uris=[u201cfile_uriu201d], format=u201cCSVu201d);’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ee24735da10>)])]
- Load data into a table partitioned by ingestion time
- code_block
- [StructValue([(u’code’, u’LOAD DATA INTO dataset_name.table_namern(col_name_1 INT64)rnPARTITION BY _PARTITIONDATErnFROM FILES (uris=[u201cfile_uriu201d], format=u201cCSVu201d);’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ee24735d090>)])]
- Load data into or overwrite one selected partition
- code_block
- [StructValue([(u’code’, u”LOAD DATA INTO dataset_name.table_namernPARTITIONS(_PARTITIONTIME = TIMESTAMP(‘2023-01-01′))rn(col_name_1 INT64)rnPARTITION BY _PARTITIONDATErnFROM FILES (uris=[u201cfile_uriu201d], format=u201cCSVu201d);”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ee24726c2d0>)])]
Sharing and managing data in a more secure way
Authorized stored procedures (preview)
A stored procedure is a collection of statements that can be called from other queries. If you need to share query results from stored procedures with specific users without giving them read access to the underlying table, the newly introduced authorized stored procedure provides you with a convenient and secure way to share data access.
How does it work?
-
Data engineers craft specific queries and grant permission on authorized stored procedures for specific analyst groups, who can then run and view query results without the read permission for the underlying table.
-
Analysts can then use authorized stored procedures to create query entities (tables, views, UDFs, etc.), call procedures, or perform DML operations.
Extended support to analyze data with more flexibility
LIKE ANY/SOME/ALL (preview)
Analysts frequently need to search against business information stored in string columns, e.g., customer names, reviews, or inventory names. Now you can use LIKE ANY/LIKE ALL to check against multiple patterns in one statement. There is no need to use multiple queries with LIKE operators in conjunction with a WHERE clause.
With the newly introduced LIKE qualifiers ANY/SOME/ALL, you can filter rows on fields that match any/or all specified patterns. This can make it more efficient for analysts to filter data and generate insights based on their search criteria.
LIKE ANY (synonym for LIKE SOME): you can filter rows on fields which match any of one or multiple specified patterns
- code_block
- [StructValue([(u’code’, u”–Filter rows that match any patterns like ‘Intend%’, ‘%intention%’ rnWITH Words ASrn (SELECT ‘Intend with clarity.’ as value UNION ALLrn SELECT ‘Secure with intention.’ UNION ALLrn SELECT ‘Clarity and security.’)rn SELECT * FROM Words WHERE value LIKE ANY (‘Intend%’, ‘%intention%’);rn/*————————+rn | value |rn +————————+rn | Intend with clarity. |rn | Secure with intention. |rn +————————*/”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ee246129a10>)])]
LIKE ALL: you can filter rows on fields which match all of the specified patterns
- code_block
- [StructValue([(u’code’, u”–Filter rows that match all patterns like ‘%ity%’, u2018%ithu2019rnWITH Words ASrn (SELECT ‘Intend with clarity.’ as value UNION ALLrn SELECT ‘Secure with identity.’ UNION ALLrn SELECT ‘Clarity and security.’)rn SELECT * FROM Words WHERE value LIKE ALL (‘%ity%’, u2018%ithu2019); rn/*———————–+rn | value |rn +———————–+rn | Intend with clarity. |rn | Secure with identity. |rn +———————–*/”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ee246129f50>)])]
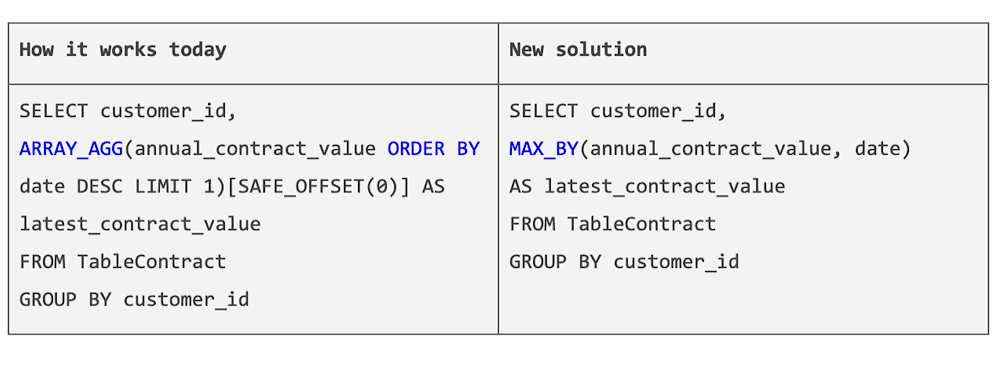
ANY_VALUE (HAVING MAX | MIN) (GA)
It’s common for customers to query for a value associated with a max or min value in a different column in the same row, e.g., to find the SKU of the best-selling product. Previously, you needed to use a combination of array_agg() and order by (), or last_value() in a window function to get the results, which is more complicated and less efficient, especially when there are duplicate records.
With ANY_VALUE(x HAVING MAX/MIN y), as well as its synonyms MAX_BY and MIN_BY, you can now easily query a column associated with the max/min value of another column, with a much cleaner and readable SQL statement.
Example: find the most recent contract value for each of your customers.
Index support for arrays & struct (GA)
Array is an ordered list of values of the same data type. Currently, to access elements in an array, you can use either OFFSET(index) for zero-based indexes (start counting at 0), or ORDINAL(index) for one-based indexes (start counting at 1). To make it more concise, BigQuery now supports a[n] as a synonym for a[OFFSET(n)]. This makes it easier for users who are already familiar with such array index access conventions.
- code_block
- [StructValue([(u’code’, u’SELECTrn some_numbers,rn some_numbers[1] AS index_1, — index starting at 0rn some_numbers[OFFSET(1)] AS offset_1, — index starting at 0rn some_numbers[ORDINAL(1)] AS ordinal_1 — index starting at 1rnFROM Sequencesrnrn/*——————–+———+———-+———–*rn | some_numbers | index_1 | offset_1 | ordinal_1 |rn +——————–+———+———-+———–+rn | [0, 1, 1, 2, 3, 5] | 1 | 1 | 0 |rn | [2, 4, 8, 16, 32] | 4 | 4 | 2 |rn | [5, 10] | 10 | 10 | 5 |’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ee246129110>)])]
Struct is a data type that represents an ordered tuple of fields of various data types. Today if there are anonymous fields or duplicate field names, it can be challenging to access field values. Similar to Array, we are introducing OFFSET(index) for zero-based indexes (start counting at 0) andORDINAL(index) for one-based indexes (start counting at 1). With this index support, you can easily get the value of a field at a selected position in a struct.
- code_block
- [StructValue([(u’code’, u’WITH Items AS (SELECT STRUCT<INT64, STRING, BOOL>(23, “tea”, FALSE) AS item_struct)rnSELECTrn item_struct[0] AS field_index, — index starting at 0rn item_struct[OFFSET(0)] AS field_offset, — index starting at 0rn item_struct[ORDINAL(1)] AS field_ordinal — index starting at 1rnFROM Itemsrnrn/*————-+————–+—————*rn | field_index | field_offset | field_ordinal |rn +————-+————–+—————+rn | 23 | 23 | 23 |rn *————-+————–+—————*/’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ee246129b50>)])]
More BigQuery features that are now GA
Finally, several BigQuery features have recently moved from preview to GA, and are now fully supported by Google Cloud. These include:
-
If you want to drop a column or rename a column, you can already run a zero-cost metadata only command DROP COLUMNor RENAME COLUMN.
In GA, we have further extended the support to table copies and copy jobs. If you have a table with a column that previously had been renamed or dropped, you can now make a copy of that table by using either CREATE TABLE COPY statement or run a copy job with the most up-to-date schema information.
Case-insensitive string collation
-
Today, you can compare or sort strings regardless of case sensitivity by specifying ‘und:ci’. This means [A,a] will be treated as equivalent characters and will precede [B. b] for string value operations. In GA, we have extended this support for aggregate functions (MIN, MAX, COUNT DISTINCT), creating views, materialized views, BI engine, and many others.
What’s next?
We will continue this journey focusing on building user-friendly SQL capabilities to help you load, analyze and manage data in BigQuery in the most efficient way. We would love to hear how you plan to use these features in your day to day. If you have any specific SQL features you want to use, please file a feature request here. To get started, try BigQuery for free.