
In today’s data-driven world, businesses need database solutions that can handle massive data volumes, deliver lightning-fast performance, and maintain near-perfect uptime. This is especially true for companies with critical workloads operating at global scale, where downtime translates directly into lost revenue and frustrated customers. In this blog post, we examine how Palo Alto Networks, a global cybersecurity leader, overcame their performance and scalability challenges by migrating their Advanced WildFire product from Apache Cassandra to Bigtable, Google Cloud’s enterprise-grade, low-latency NoSQL database service, achieving 5x lower latency and cutting their total cost of ownership by half. Read on to learn how they went about this migration.
At Google, Bigtable has been serving internal systems and external customers for over a decade. Google Cloud’s goal with Bigtable is to solve the industry’s most complex use cases and also reach a broader developer audience. Recent Bigtable features are significant steps in that direction:
- Bigtable Data Boost: This breakthrough technology delivers high-performance, workload-isolated, on-demand analytical processing of transactional data. It allows you to execute queries, ETL jobs, and train ML models directly and as frequently as needed on your transactional data without disrupting your operational workloads.
- Authorized views: This feature allows multiple teams to leverage the same tables securely and share data from your databases, fostering collaboration and efficient data utilization.
- Distributed counters: This functionality aggregates data at write time to help you process high-frequency event data like clickstreams directly in your database to deliver real-time operation metrics and machine learning features consistently and at scale.
- SQL support: With over 100 SQL functions now available directly in Bigtable, developers can leverage Bigtable’s performance and scalability using their existing skills.
These enhancements along with existing features make Bigtable the database of choice for a variety of business-critical workloads, including Advanced WildFire.
From Cassandra to Bigtable at Palo Alto Networks
Palo Alto Networks’ Advanced WildFire is the industry’s largest cloud-based malware protection engine, analyzing over 1 billion samples monthly to protect organizations worldwide from sophisticated and evasive threats. To do so, it uses over 22 different Google Cloud services across 21 regions. Palo Alto Networks’ Global Verdict Service (GVS), a core component of WildFire, relies on a NoSQL database to process vast amounts of data that needs to be highly available for service uptime. Initially, when developing Wildfire, Apache Cassandra seemed like a suitable choice. However, as data volumes and performance demands grew, several limitations emerged:
- Performance bottlenecks: High latency, frequent timeouts, and excessive CPU usage, often triggered by compaction processes, hampered performance and impacted the user experience.
- Operational complexity: Managing a large Cassandra cluster demanded specialized expertise and significant overhead, leading to increased management, complexity, and costs.
- Replication challenges: Achieving low-latency replication across geographically dispersed regions proved difficult, requiring a complex mesh architecture to mitigate lag.
- Scaling difficulties: Scaling Cassandra horizontally was cumbersome and time-consuming, with node upgrades requiring significant effort and downtime.
To address these limitations, Palo Alto Networks decided to migrate GVS to Bigtable. This decision was fueled by Bigtable’s promise of:
- High availability: Bigtable delivers a 99.999% availability SLA, ensuring virtually uninterrupted service and maximum uptime.
- Scalability: Its horizontally scalable architecture allows for near-infinite scalability, readily accommodating Palo Alto Networks’ ever-growing data demands.
- Performance: Bigtable offers single-digit millisecond latency for read and write operations, resulting in a significantly improved user experience and application responsiveness.
- Cost efficiency: As a fully managed service, Bigtable reduces operational costs compared to managing a large, complex Cassandra cluster.
The migration to Bigtable yielded remarkable results for Palo Alto Networks:
- 5x lower latency: The switch to Bigtable delivered a fivefold reduction in latency, leading to a dramatically improved user experience and application responsiveness.
- 50% lower cost: Palo Alto Networks achieved a substantial 50% cost reduction thanks to Bigtable’s efficient, managed service model.
- Increased availability: Availability jumped from 99.95% to an impressive 99.999%, ensuring near-constant uptime and minimizing service disruptions.
- Simplified architecture: The complexities of the mesh architecture required for Cassandra replication were eliminated, leading to simpler and more manageable infrastructure.
- Fewer production issues: The migration resulted in a remarkable 95% reduction in production issues, translating into smoother operations and fewer disruptions.
- Enhanced scalability: Bigtable provided the capacity to support 20 times the scale compared to their previous Cassandra setup, providing ample room for growth.
And the best part is that migrating from Cassandra to Bigtable can be a straightforward process — read on to see how.
The Cassandra to Bigtable migration
While transitioning from Cassandra to Bigtable, Palo Alto aimed to preserve the integrity of their data and continue operations. The following is an overview of the steps in the migration process, which spanned several months:

-
Initial data migration:
-
Start by creating a Bigtable instance, clusters, and tables to receive the migrated data.
-
For every table, use the data migration tool to extract data from Cassandra and load it into Bigtable. The row keys should be designed with read requests in mind. The general rule of thumb is that the Bigtable row key should be the same as Cassandra’s primary key for a table.
-
Ensure that the data types, columns and column families in Bigtable match those in Cassandra.
-
During this phase, continue writing new data to the Cassandra cluster.
-
Data integrity checks:
-
Compare the data in Cassandra against the data in Bigtable to verify that the migration was successful using data validation tools or custom scripts. Address any discrepancies or data inconsistencies that are identified.
-
Enable dual writes:
-
Implement dual writes to Bigtable (along with Cassandra) for all tables.
-
Use application code to route write requests to both databases.
-
Live data integrity checks:
-
Conduct regular data integrity checks on live data to ensure that the data in Cassandra and Bigtable remains consistent using continuous scheduled scripts.
-
Monitor the results of the data integrity checks and investigate any discrepancies or issues that are identified.
-
Redirect reads:
-
Gradually shift read operations from Cassandra to Bigtable by updating the existing application code and/or load balancers.
-
Monitor the performance and latency of read operations.
-
Stop dual writes:
-
Once all read operations have been redirected to Bigtable, cease writing to Cassandra, and ensure that all write requests are directed to Bigtable.
-
Decommission Cassandra:
-
Safely shut down the Cassandra cluster after all data has been migrated and read operations have been redirected to Bigtable.
The workflow and approach is summarized in the diagram below:
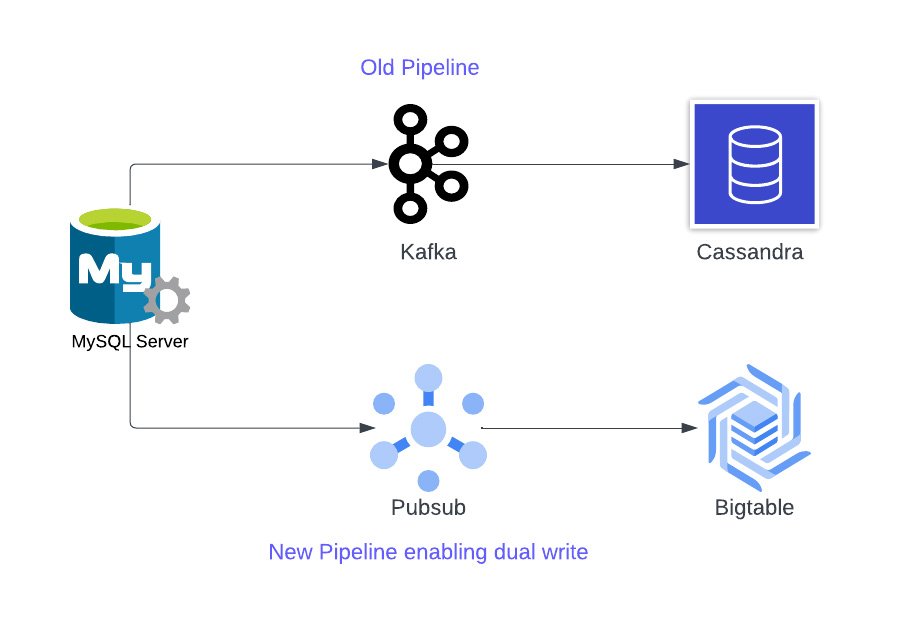
Tools for migrating existing data
Palo Alto Networks used the following tools during the migration process:
-
Use the ‘dsbulk’ tool for data unloading: The ‘dsbulk’ tool can export data from Cassandra into CSV files. These files are loaded to Cloud Storage buckets for further ingestion.
-
Reference: Datastax dsbulk Documentation
-
Create Dataflow pipelines for loading into Bigtable: Dataflow pipelines were deployed to load the CSV files into Bigtable within a test environment.
-
Reference: Google Cloud Dataflow CSV Import Guide

At the same time, given the critical nature of data migration, Palo Alto adopted a two-step approach: an initial dry-run migration followed by the final migration. This strategy helped mitigate risks and refine the process.
Reasons for a dry-run migration:
-
Evaluate impact: Assess the effects of the ‘dsbulk’ tool on the live Cassandra cluster, especially under load, and adjust configurations accordingly.
-
Identify issues: Detect and resolve potential issues associated with the massive data volume (in the terabytes).
-
Estimate time: Gauge the time required for migration to plan for live traffic handling during the final migration.
Then, when it was ready, it moved on to the final migration.
Final migration steps:
-
Deploy pipeline services:
-
Reader service: Reads data from all MySQL servers and publishes to a Google Cloud Pub/Sub topic.
-
Writer service: Writes data to Bigtable from a Pub/Sub topic.
-
Set cut-off time: Define a cut-off time and repeat the data migration process.
-
Initiate services: Start both the writer and reader services.
-
Conduct final checks: Perform comprehensive data integrity checks to ensure accuracy and completeness.
This structured approach ensures a smooth transition from Cassandra to Bigtable, maintaining data integrity and minimizing disruption to ongoing operations. With planning, Palo Alto Networks was able to ensure that migration was both efficient and reliable at each phase.
Migration best practices
Migrating from one database system to another is a complex undertaking, requiring careful planning and execution. Here are some best practices for migrating from Cassandra to Bigtable that Palo Alto employed:
- Data model mapping: Analyze and map your existing Cassandra data model to a suitable Bigtable schema. Bigtable offers flexibility in schema design, allowing for efficient data representation.
- Data migration tools: Use data migration tools like the open-source “Bigtable cbt” tool to streamline the data transfer process and minimize downtime.
- Performance tuning: Optimize your Bigtable schema and application code to maximize performance and fully leverage Bigtable’s capabilities.
- Application code adaptation: Adapt your application code to interact with Bigtable’s API and leverage its unique features.
That said, here are some potential pitfalls to watch out for:
- Schema mismatch: Ensure that the Bigtable schema accurately reflects the data structures and relationships in your Cassandra data model.
- Data consistency: Carefully plan and manage the data migration process to ensure data consistency and avoid data loss.
Get ready to migrate to Bigtable
All told, Palo Alto Networks’ migration to Bigtable was transformative. If your organization is grappling with database challenges like performance bottlenecks, scalability limitations, or operational complexity, consider Bigtable. Recent enhancements including Bigtable Data Boost, authorized views, distributed counters, and SQL support, make it even more compelling for diverse workloads.
Ready to experience the benefits of Bigtable for yourself? Now, Google Cloud offers a seamless migration path from Cassandra to Bigtable, utilizing Dataflow as the primary dual-write tool. This Apache Cassandra to Bigtable template simplifies the setup and execution of your data replication pipeline. Start your journey today and unlock the potential of a highly scalable, performant, and cost-effective database solution.