
It’s a great time for organizations innovating with AI. Google recently launched Gemini, our largest and most capable AI model, followed by Gemma, a family of lightweight, state-of-the art open models built from research and technology that we used to create the Gemini models. Gemma models achieve best-in-class performance for their size (Gemma 2B and Gemma 7B) compared to other open models, and are pre-trained and equipped with instruction-tuned variants to enable research and development. The release of Gemma and our updated platform capabilities are the next phase of our commitment to making AI more open and accessible to developers on Google Cloud. Today, let’s take a look at the enhancements we’ve made to Google Kubernetes Engine (GKE) to help you serve and deploy Gemma on GKE Standard as well as Autopilot:
-
Integration with Hugging Face, Kaggle and Vertex AI Model Garden: If you are a GKE customer, you can deploy Gemma by starting in Hugging Face, Kaggle or Vertex AI Model Garden. This lets you easily deploy models from your preferred repositories to the infrastructure of your choice.
-
GKE notebook experience using Colab Enterprise: Developers who prefer an IDE-like notebook environment for their ML project can now deploy and serve Gemma using Google Colab Enterprise.
-
A cost-efficient, reliable and low-latency AI inference stack: Earlier this week we announced JetStream, a highly efficient AI-optimized large language model (LLM) inference stack to serve Gemma on GKE. Along with JetStream, we introduced a number of cost- and performance-efficient AI-optimized inference stacks for serving Gemma across ML Frameworks (PyTorch, JAX) powered by Cloud GPUs or Google’s purpose-built Tensor Processor Units (TPU). Earlier today we published a performance deepdive of Gemma on Google Cloud AI optimized infrastructure for training and serving generative AI workloads.
Now, whether you are a developer building generative AI applications, an ML engineer optimizing generative AI container workloads, or an infrastructure engineer operationalizing these container workloads, you can use Gemma to build portable, customizable AI applications and deploy them on GKE.
Let’s walk through each of these releases in more detail.
Hugging Face, Vertex AI Model Garden and Kaggle integration
Regardless of where you get your AI models, our goal is to make it easy for you to deploy them on GKE.
Hugging Face
Earlier this year, we signed a strategic partnership with Hugging Face, one of the preferred destinations for the AI community, to provide data scientists, ML engineers and developers with access to the latest models. Hugging Face launched the Gemma model card, allowing you to deploy Gemma from Hugging Face directly to Google Cloud. Once you click the Google Cloud option, you will be redirected to Vertex Model Garden, where you can choose to deploy and serve Gemma on Vertex AI or GKE.
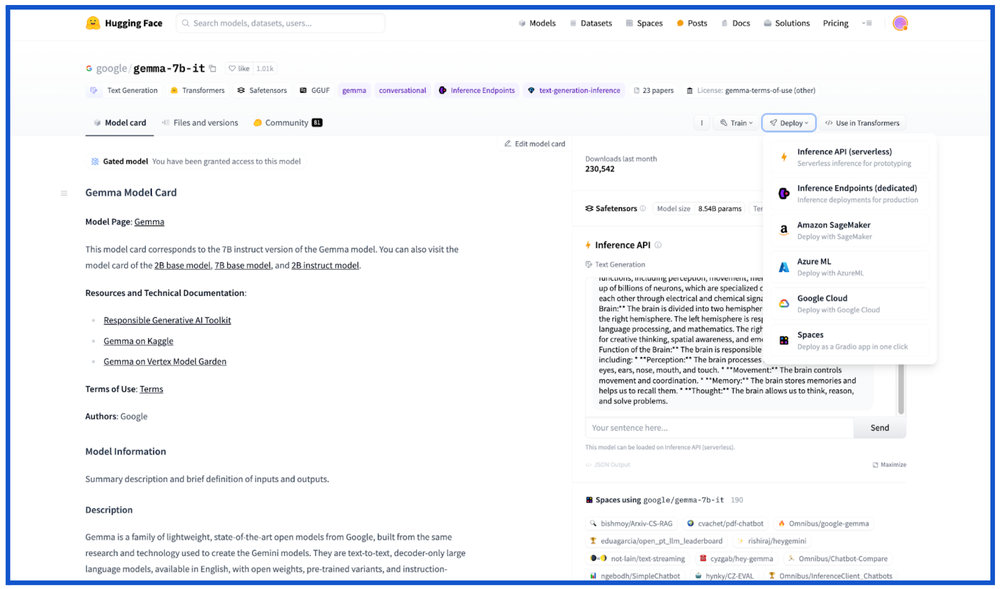
Vertex Model Garden
Gemma joins 130+ models in Vertex AI Model Garden, including enterprise-ready foundation model APIs, open-source models, and task-specific models from Google and third parties.
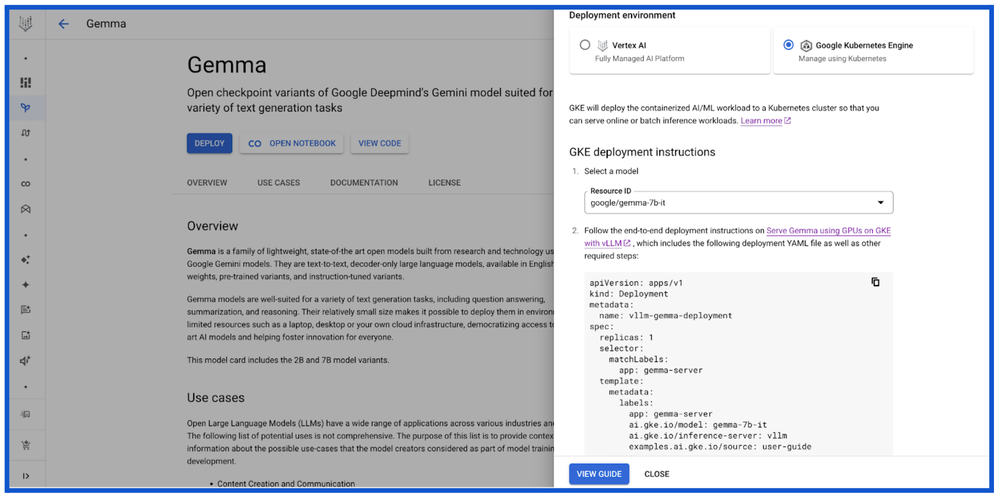
Kaggle
Kaggle allows developers to search and discover thousands of trained, ready-to-deploy machine learning models in one place. The Gemma model card on Kaggle provides a number of model variations (PyTorch, FLAX, Transformers, etc) to enable an end-to-end workflow for downloading, deploying and serving Gemma on a GKE cluster. Kaggle customers can also “Open in Vertex,” which takes them to Vertex Model Garden where they can see the option to deploy Gemma either on Vertex AI or GKE as described above. You can explore real-world examples using Gemma shared by the community on Gemma’s model page on Kaggle.
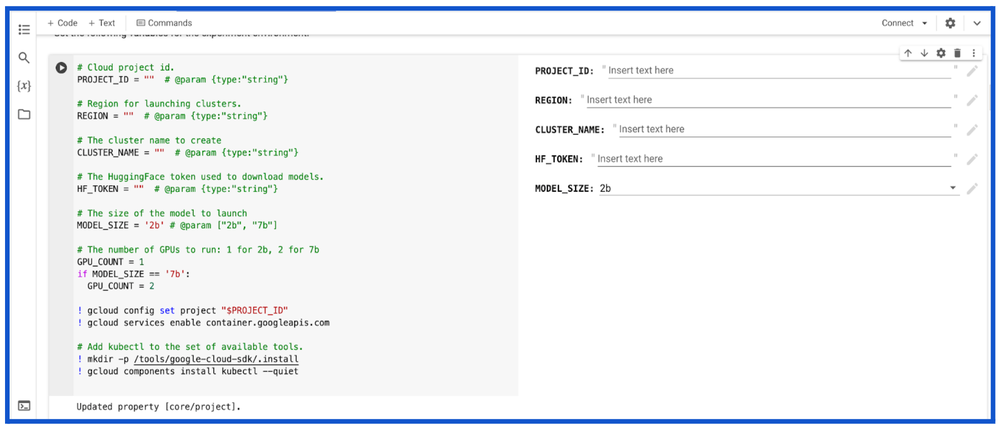
Google Colab Enterprise notebooks
Developers, ML engineers and ML practitioners can also deploy and serve Gemma on GKE using Google Colab Enterprise notebooks via Vertex AI Model Garden. Colab Enterprise notebooks come with pre-populated instructions in the code cells, providing the flexibility to deploy and run inference on GKE using an interface that is preferred by developers, ML engineers and scientists.
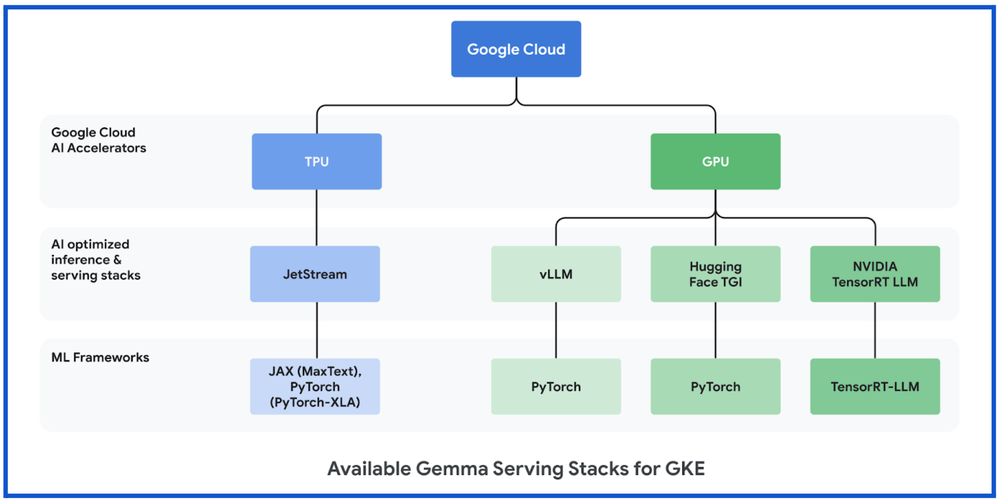
Serve Gemma models on AI-optimized infrastructure
When running inference at scale, performance per dollar and cost of serving are critical. Powered by an AI-optimized infrastructure stack equipped with Google Cloud TPUs and GPUs, GKE enables high-performance and cost-efficient inference for a broad range of AI workloads.
“GKE empowers our ML pipelines by seamlessly integrating TPUs and GPUs, allowing us to leverage the strengths of each for specific tasks and reduce latency and inference costs. For instance, we efficiently process text prompts in batches using a large text encoder on TPU, followed by employing GPUs to run our in-house diffusion model, which utilizes the text embeddings to generate stunning images.” – Yoav HaCohen, Ph.D, Core Generative AI Research Team Lead, Lightricks
We are excited to extend these benefits to workloads that are equipped with Gemma on GKE.
Gemma on GKE with TPUs
If you prefer to use Google Cloud TPU accelerators with your GKE infrastructure, several AI-optimized inference and serving frameworks also now support Gemma on Google Cloud TPUs, and already support the most popular LLMs. These include:
JetStream
For optimizing inference performance for PyTorch or JAX LLMs on Google Cloud TPUs, we launched JetStream(MaxText) and JetStream(PyTorch-XLA), a new inference engine specifically designed for LLM inference. JetStream represents a significant leap forward in both performance and cost efficiency, offering strong throughput and latency for LLM inference on Google Cloud TPUs. JetStream is optimized for both throughput and memory utilization, providing efficiency by incorporating advanced optimization techniques such as continuous batching, int8 quantization for weights, activations and KV cache. JetStream is the recommended TPU inference stack from Google.
Get started with JetStream inference for Gemma on GKE and Google Cloud TPUs with this tutorial.
Gemma on GKE with GPUs
If you prefer to use Google Cloud GPU accelerators with your GKE infrastructure, several AI-optimized inference and serving frameworks also now support Gemma on Google Cloud GPUs, and already support the most popular LLMs. These include:
vLLM
Used to increase serving throughput for PyTorch generative AI users, vLLM is a highly optimized open-source LLM serving framework. vLLM includes features such as:
-
An optimized transformer implementation with PagedAttention
-
Continuous batching to improve the overall serving throughput
-
Tensor parallelism and distributed serving on multiple GPUs
Get started with vLLM for Gemma on GKE and Google Cloud GPUs with this tutorial.
Text Generation Inference (TGI)
Designed to enable high-performance text generation, Text Generation Inference (TGI) is a highly optimized open-source LLM serving framework from Hugging Face for deploying and serving LLMs. TGI includes features such as continuous batching to improve overall serving throughput, and tensor parallelism and distributed serving on multiple GPUs.
Get started with Hugging Face Text Generation Inference for Gemma on GKE and Google Cloud GPUs with this tutorial.
TensorRT-LLM
To optimize inference performance of the latest LLMs on Google Cloud GPU VMs powered by NVIDIA Tensor Core GPUs, customers can use NVIDIA TensorRT-LLM, a comprehensive library for compiling and optimizing LLMs for inference. TensorRT-LLM supports features like paged attention, continuous in-flight batching, and others.
Get started with NVIDIA Triton and TensorRT LLM backend on GKE and Google Cloud GPU VMs powered by NVIDIA Tensor Core GPUs with this tutorial.
Train and serve AI workloads your way
Whether you’re a developer building new gen AI models with Gemma, or choosing infrastructure on which to train and serve those models, Google Cloud provides a variety of options to meet your needs and preferences. GKE provides a self-managed, versatile, cost-effective, and performant platform on which to base the next generation of AI model development.
With integrations into all the major AI model repositories (Vertex AI Model Garden, Hugging Face, Kaggle and Colab notebooks), and support for both Google Cloud GPU and Cloud TPU, GKE offers several flexible ways to deploy and serve Gemma. We look forward to seeing what the world builds with Gemma and GKE. To get started, please refer to the user guides on the Gemma on GKE landing page.