
The investment management business is more data-driven than ever. The Portfolio Management Group (PMG) at BlackRock — the world’s largest financial asset management company — is responsible for a wide range of investment strategies, using data at all stages in the process to make investment decisions, manage multi-asset portfolio risk, and keep track of portfolio performance. As data used for the investment process continues to grow in volume and variety, data operations become increasingly complex and challenging, requiring a variety of skills and tools to manage.
To adapt to the rapidly changing asset management environment, data operations teams need to improve the efficiency, accuracy, and flexibility of their data processing through customizable data pipelines to extract and organize information from a growing number of disparate data sources. These include traditional financial datasets and alternative datasets. By making data more consumable, the data operations teams can empower investment and research teams — i.e., data consumers — to make better decisions at the speed of business.
BlackRock’s Data Strategy & Solutions team set out to build a custom solution for data operations by harnessing the power of Google Cloud to automate data profiling and to identify data quality issues early, such as missing values, duplicate records, and other outliers. The solution uses a unified architecture that can calibrate to the evolving data landscape in the asset management industry. This in turn improves the quality, speed, and usability of the data used by the investment and research teams.
Architecting the solution on Google Cloud
BlackRock built a platform architecture using BigQuery as the data fabric to support a standard model for all data across internal and external sources, along with seamless integration with other services including Cloud Storage, Pub/Sub, and Cloud Functions, to automate data pipelines that proactively identify data errors and inconsistencies. The following illustration shows the architecture at a high level.
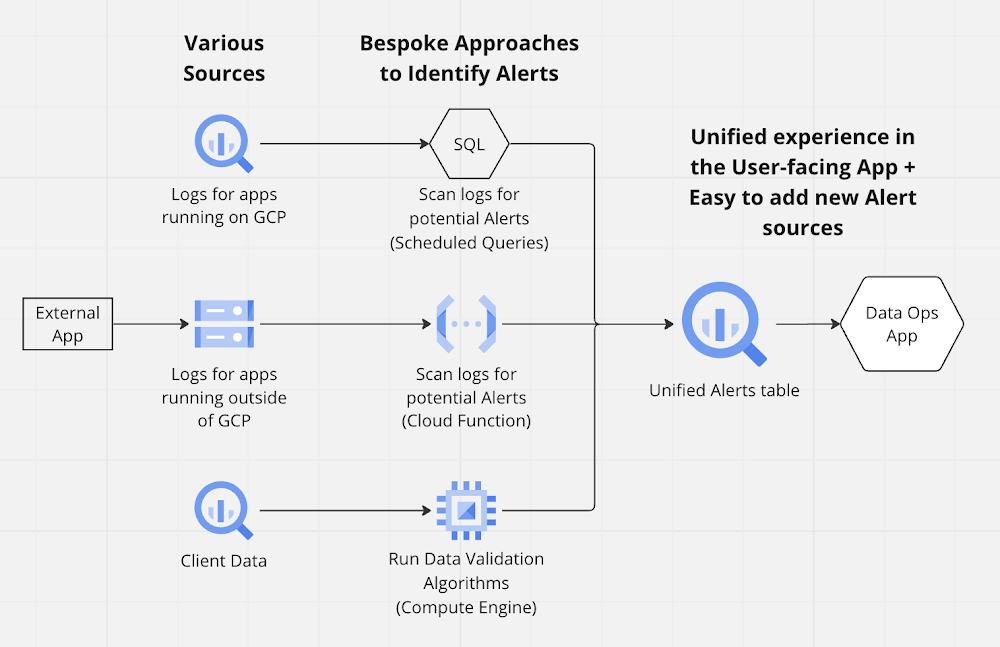
Without this unified solution, the data operations team would have to check feeds, databases, application logs, and other data sources and then manually reconcile inconsistencies that are susceptible to human error. That would make alert prioritization more difficult and maintenance more of a burden. However, the solution unifies all sources in a single location and stores them in BigQuery as a common data model with standardized extensible data schemas. Data pipelines with customized alert algorithms run through scheduled queries, Cloud Functions, and Compute Engine, which allows the data to be prioritized and acted on much faster through automated data flows between data managers and data consumers.
As a result, the source applications remain unchanged. Platform engineers have maximum flexibility to create bespoke algorithms for alerts as long as the algorithm output matches the standard data model. As shown in the diagram above, the data operations team has a unified experience to identify potential data issues and resolve them through a common interface at speed and at scale.
Principles of the platform include:
-
Simplicity and scalability – BigQuery serverless architecture eliminates the overhead with predictable query performance at scale (hundreds of millions of records) with native support for real-time and batch processes to identify and resolve data quality issues in real time.
-
Extensibility – Stand up new data pipelines and workflows with ease to enable new data sources through native integration between Cloud Storage, Pub/Sub, Cloud Functions and BigQuery.
-
Future-proofing – Self-optimizing BigQuery offers a fully integrated intelligent data fabric with support for structured, unstructured, and spatial data with “built-in” AI/ML capabilities, which unifies the distributed data to help automate data management and power analytics at scale.
Realizing the benefits
Every month, BlackRock’s Data Strategy & Solutions team processes over 30,000 datasets, while more than 6,000 alerts are actioned to provide consistent, high-quality data to the company’s investment teams. This enables them to be more agile in responding to market changes.
The unified solution helps prioritize access across six data sources and 15 unique alert algorithms, allowing urgent issues to be addressed 30% faster by presenting the decision-making information through a consistent interface.
Improved data operations processes have reduced the time it takes to add new data sources and alerts from days to hours. This represents an 80% reduction in onboarding time. As a result, data engineers can have an additional 20 hours a month to focus on other strategic tasks, such as developing new data products and services.
Our data organization successfully implemented DataOps best practices to adapt to the changing data landscape, reduce the time to value, and minimize the total cost of ownership.
By creating a unified solution on Google Cloud, the BlackRock Data Strategy & Solutions team can scale data consumption by providing a reliable, scalable, and secure platform for storing, processing, and analyzing data. The data processing and operations architecture can integrate simply with rapidly developing Google Cloud capabilities, including generative AI technology, and it will continue to transform how our investment teams interact with data to identify opportunities, assess risk, and make better investment decisions.
For more information on how Google Cloud is benefitting the capital markets industry, visit this page.