This post is the first in a short series of blog posts about Feast on Google Cloud. In this first blog post, we describe the benefits of using Feast, a popular open source ML feature store, on Google Cloud. In our second blog post, we’ll provide a simple, introductory tutorial for building a product recommendation system with Feast on Google Cloud.
Data scientists and other ML practitioners are increasingly relying on a new kind of data platform: the ML feature store. This specialized offering can help organizations simplify the management of their ML feature data and make their ML model development efforts more scalable. Feature stores take on the core tasks of managing the code that organizations use to generate ML features, running this code on unprocessed data, and deploying these features to production in user-facing applications. Feature stores typically integrate with a data warehouse, object storage, and an operational storage system for application serving.
Feature stores can be very valuable for organizations whose ML teams need to reuse the same feature data in multiple ML models for different application use cases. They can be especially valuable when these ML models must be retrained frequently using very recent data to ensure that model predictions remain up-to-date for app users.
For example, let’s consider a movie streaming service that has a dozen different ML models running in production to support use cases like personalized recommendations, search, and email notifications. If we assume that each ML model is owned by a different team, there’s a very high likelihood that each team could benefit from having many of the same ML features (e.g. regularly updated vector embeddings that include the most recent movies watched by user, by title, and by genre) instead of each having to build their own features from scratch and take on the costs of maintaining the same critical infrastructure a dozen different times.
Every organization and ML project has unique requirements, and there are a wide variety of effective ML platforms available to support these different needs. For example, some Google Cloud customers choose Vertex AI Feature Store, a fully-managed feature store that provides a centralized repository for organizing, storing, and serving ML features and integrates directly with Vertex AI’s broad range of features and capabilities. Alternatively, organizations with more specialized requirements can choose to build a custom ML platform based on the always-on, petabyte-scale capabilities of Google Cloud managed services like BigQuery and Cloud Bigtable.
Then there’s Feast, a popular, customizable open-source ML feature store that solves many of the most difficult challenges that keep organizations from effectively scaling their ML development efforts. To support Google Cloud customers who’d like an end-to-end solution for Feast on Google Cloud, Tecton, a contributor to Feast, released an open-source integration for Feast on Bigtable last year, expanding on their existing integrations with BigQuery and Google Kubernetes Engine (GKE) for feature-store use cases.
Feast has been adopted by a wide variety of organizations in different industries including in retail, media, travel, and financial services. Among Google Cloud customers, Feast has been adopted at scale in industry verticals like consumer internet, technology, retail, and gaming. Along the way, customers have unlocked significant ML development velocity and productivity benefits that enhance the value of the applications that they deliver to their own customers, partners, and end-users.

Why Feast?
Feast provides a powerful single data access layer that abstracts ML feature storage from feature retrieval, ensuring that ML teams’ models remain portable throughout the model development and deployment process — from training to serving, from batch to real-time, and from one data storage system to another.
Compare this to organizations who opt to build their own, homegrown feature stores. These projects often achieve quick success with focused efforts by small teams, but can quickly run into challenges when they try to scale their ML development efforts to additional teams within their respective organizations. These new teams may learn very quickly that reusing the existing feature store as-is is impractical, and instead – by necessity – decide to “reinvent the wheel” and build their own siloed feature pipelines versions to meet deadlines. As this process repeats itself from team to team, the organization’s ML stack and ML development practices quickly become fragmented, preventing future teams from reusing the ML features, data pipelines, Notebooks, data access controls, or other tooling that already exists. This pattern results in further duplication of development efforts and tooling, causing rapid growth in infrastructure costs, while also adding time-to-market bottlenecks for new models, each of which must be developed from scratch.
Feast addresses these common organization-level ML scaling challenges head-on, enabling customers to achieve far greater leverage from their ML investments by:
-
Standardizing data workflows, development processes, and tooling across different teams by integrating directly with the tools and infrastructure that these teams already use for key steps like feature transformation, data storage, monitoring, and modeling
-
Accelerating time-to-market for new ML projects by bootstrapping them with a reusable library of curated, production-ready features for data warehouses such as BigQuery that are readily discoverable by anyone within the customer organization
-
Productionizing features with centrally-managed, reusable data pipelines and integrating them with a low-latency online storage layer, such as Bigtable, and the online storage layer’s feature serving endpoints
-
Eliminating expensive data inconsistencies across teams’ data analysis, training, and serving environments, including across BigQuery and Bigtable, improving model point-in-time accuracy and prediction quality, while also avoiding the protracted debugging efforts that would otherwise be necessary to identify the source of these data inconsistencies

Feast’s Bigtable integration
Feast’s Bigtable integration builds on Feast’s existing integration with BigQuery and provides Google Cloud customers with a more turnkey single data-access layer on top of BigQuery and Bigtable that streamlines the critical “last mile” of production ML data materialization. With the Feast’s Bigtable integration, data scientists and other ML practitioners can transform and productionize their analytical data in BigQuery for low-latency training and inference serving on Bigtable at any scale without having to build or update custom pipelines, so they can realize the value of their efforts in production sooner.
What’s more, Bigtable’s highly flexible replication capabilities now allow ML teams to serve Feast feature data to end-users in up to eight Google Cloud regions at the same time to (a) reduce serving latency and (b) provide automatic request routing to the nearest replica to support Disaster Recovery (DR) requirements.
The role of feature serving in an ML feature store
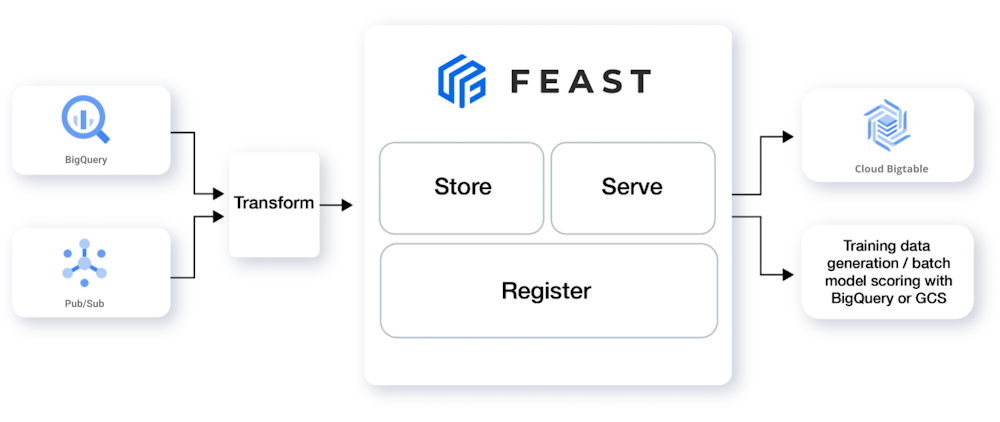
A high-quality feature store typically consists of the following components, as shown in the diagram below.
-
Storage: Feature stores persist feature data to support retrieval through feature serving layers. They typically contain an offline storage layer, such as BigQuery or Cloud Storage for ML model training as well as to provide ML model transparency and explainability to support customers’ internal ML model governance practices and policies.
-
Serving: Feature stores like Feast, through the abstractions they provide, serve feature data to the ML models that app developers integrate with their applications, a step that’s also known as feature materialization. To ensure that developers’ apps can respond quickly to the most up-to-date model predictions (e.g. to provide fresh content recommendations to end-users, show more relevant ads, or to reject fraudulent credit card payment attempts), a high-performance API backed by a low-latency database like Bigtable is essential.
-
Registry: a feature repository that acts as a centralized source of truth for customers’ ML features and contains standardized feature definitions and metadata to enable different teams to reuse existing features for different ML use cases and applications.
-
Transformation: ML applications need to incorporate the freshest data into feature values using batch or stream processing frameworks like Spark, Dataflow, or Pub/Sub so that ML models generate the most timely and relevant predictions for end users. With Feast, these transformations can be configured based upon common feature definitions and similar metadata in a common feature registry
-
Monitoring (not shown): operational monitoring, and especially data correctness and data-quality monitoring to detect behavior like training-serving skew and model drift are essential parts of any machine learning system. Feature stores like Feast can calculate metrics on the features they store and serve that describe correctness and quality to communicate the overall health of an ML application and help determine when intervention is necessary.
Feast in action on Google Cloud
Google Cloud customers use many of the following products in combination with Feast:
-
BigQuery: Google Cloud’s petabyte-scale, fully managed, serverless data warehouse enables scalable analysis over petabytes of data and is a popular choice for offline feature storage, training and evaluation
-
Cloud Bigtable: Cloud Bigtable is Google Cloud’s fully managed, scalable NoSQL database service for large analytical and operational workloads and is a highly effective solution for online prediction and feature serving
-
Dataflow: Dataflow is Google Cloud’s fully managed streaming analytics service, which minimizes latency, processing time, and cost through autoscaling and batch processing to extract, transform, and load data to and from data warehouses like BigQuery and databases like Cloud Bigtable to support use cases like ML feature transformation
-
Dataproc: Dataproc is a fully managed and highly scalable service for running Apache Spark and 30+ open source tools and frameworks. Spark ranks among the most popular batch and stream processing frameworks for ML practitioners.
-
Pub/Sub: Pub/Sub is Google Cloud’s asynchronous and scalable messaging service for streaming analytics and data integration pipelines to ingest and distribute data and can be an excellent fit for on-demand streaming transformations to ML feature data
Thanks for reading! In the second installment of this series of blog posts, we’ll build a prototype Feast feature store for an ML personalization use case using BigQuery, Cloud Bigtable, and Google Colab.
Learn more
For more information about Feast, please visit Feast here. As a developer, you can also get started with pip install "feast[gcp]" and begin using a bootstrapped feature store on Google Cloud with feast init -t gcp
For more information about installing Feast for Bigtable, click here. To learn more about how Feast works with BigQuery, see here.
About Feast
Feast is a popular open source feature store that reuses organizations’ existing infrastructure to manage and serve machine learning features to realtime models. Feast enables organizations to consistently define, store, and serve ML features and decouple ML from data infrastructure.
About Tecton
Tecton is the main open source contributor to Feast. Tecton also offers a new, fully-managed feature platform for real-time machine learning on Google Cloud. For more information about this new platform, please see this announcement.
About Google Cloud
Google Cloud accelerates every organization’s ability to digitally transform its business and industry. We deliver enterprise-grade solutions that leverage Google’s cutting-edge technology and tools to help developers build more sustainably. Customers in more than 200 countries and territories turn to Google Cloud as their trusted partner to enable growth and solve their most critical business problems.