
At Google Cloud Next ’26 we announced Cloud Storage Rapid, a family of object storage capabilities for data-intensive workloads like AI and analytics. Out of the gate, Cloud Storage Rapid consists of Rapid Bucket (formerly Rapid Storage), a high-performance zonal object storage offering, and Rapid Cache (formerly Anywhere Cache), which accelerates reads on-demand and colocates compute and data for workloads in existing buckets.
Cloud Storage Rapid is our response to the generational shift in how organizations build with AI. Teams are training trillion-parameter models, deploying inference at global scale, and building autonomous agents that reason over vast amounts of enterprise data. While accelerators like GPUs and TPUs often get the spotlight, they have a critical dependency: storage.
Storage is the engine that feeds accelerators during training, and the fast-access layer that makes real-time inference responsive. But as models scale, storage performance can be a bottleneck. Every time an AI/ML cluster waits on a data read or a checkpoint write stalls, you are paying for expensive compute cycles that aren’t doing useful work.
Historically, AI/ML practitioners have had to choose between the specialized performance of a niche, zonal storage system, and the reliability and scale of a global object store like Google Cloud Storage. Many developers value Cloud Storage for its simplicity, scalability, reliability, and cost-effectiveness, but as the AI era has progressed, they’ve been throwing hotter and hotter workloads at it, running training and inference workloads with thousands of GPUs and TPUs. We’ve reached a performance tipping point that traditional object storage was never meant to handle. The Rapid family provides multiple options for co-locating compute workloads directly with high-performance zonal storage. It minimizes I/O bottlenecks that can block accelerators, so that your GPUs and TPUs stay fully saturated and productive. In this blog, let’s take a closer look at Cloud Storage Rapid’s capabilities.
Rapid Bucket
Rapid Bucket (GA), helps Cloud Storage meet the evolving demands of massive-scale generative AI, analytics, and other high-performance workloads. It does so by leveraging Colossus, the Google distributed storage system that powers Gemini and YouTube, to provide massive read/write performance and ultra-low latency in a dedicated object storage zonal bucket.
Lightning-fast performance
By combining the sub-millisecond latency of block-like storage, the throughput of a parallel filesystem, and the scalability and ease of use of object storage, Rapid Bucket provides high performance from the same Cloud Storage that you know and love.
Highlights include:
-
Ultra-low latency: Achieve up to 20 million queries per second and sub-millisecond latency.
-
Massive scalability: Rapid Bucket delivers 15+ TB/s of aggregate read throughput from a single Rapid zonal bucket.
-
New semantics: Enable higher performance with new capabilities such as native appends, unlimited readers (while writing!), and vectored reads.
Optimized for AI and analytics
You can use Rapid Bucket for a variety of demanding scenarios, including AI/ML data preparation, training, checkpointing, batch and streaming analytics processing, and optimizing distributed database architectures.
Key benefits include:
-
Optimized accelerator utilization: With Rapid Bucket, we observed 50% reduced blocked GPU time and up to 2.5x faster data loading for multi-modal training runs.
-
Faster checkpointing: Rapid Bucket makes checkpoint restores up to 5x faster and writes 3.2x faster compared to traditional object storage. This ensures faster recovery from workload interruptions, minimizes wasted accelerator time, and increases overall efficiency.
>5x faster checkpoint restores with Rapid Bucket

>3.2x faster checkpoint writes with Rapid Bucket

You can get started with Rapid Bucket here.
Rapid Cache
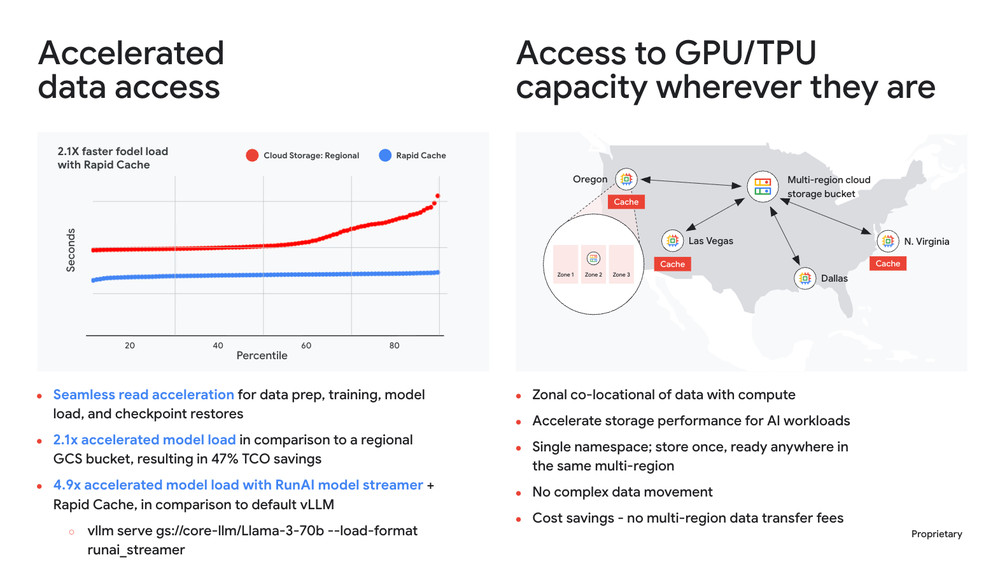
Originally announced at Cloud Next ‘25, Rapid Cache accelerates bandwidth for AI/ML workloads like data prep, training, and bursty model loading for inference, delivering an aggregate read throughput of 2.5 TB/s for your existing buckets — with no code changes. For inference workloads, we’ve observed that Rapid Cache provides up to 2.1x (114%) accelerated model load, resulting in 47% TCO savings.
When combined with multi-region buckets, customers can flexibly access GPUs and TPUs distributed across regions in a geo, while maintaining a single bucket namespace. This eliminates the need for manually orchestrated data movements between buckets, while benefitting from zonally co-located high performance.
New: Rapid Cache ingest on write
Customers at some of the world’s largest frontier AI/ML labs told us that they were looking for ways to accelerate reads immediately after a write, such as checkpoint restore workloads or a data prep pipeline that then feeds training. Before, caching the data required an initial read to trigger ingestion, which was served directly from the bucket at standard performance.
Rapid Cache’s new ingest on write feature solves this by simultaneously writing data to the Rapid Cache as it is being written to a Cloud Storage bucket. This proactive approach eliminates the initial cache-miss penalty, and helps workloads benefit from an immediate cache hit on the very first read. This provides up to 2.2x faster checkpoint restore times, allowing training clusters to recover faster from interruption.

To enable ingest on write, simply modify the ingestion criteria of your existing Rapid Cache.
Rapid Cache’s simplicity and performance has resulted in explosive adoption. In just one year since General Availability, customers have deployed thousands of Rapid Caches with a 20x growth in caches deployed, In fact,Rapid Cache serves up to 20% of Cloud Storage’s global egress. Cutting-edge AI/ML customers deploy their workloads on Rapid Cache, including Anthropic who uses Rapid Cache to improve the resilience of their cloud workload by co-locating data with TPUs in a single zone and providing dynamically scalable read throughput up to 2.5TB/s.

Case study: Thinking Machines Lab
Thinking Machines Lab is an artificial intelligence research and product company. Its mission is to make AI systems that are adaptable and customizable, building a future where everyone has access to the knowledge and tools to make AI work for their unique needs and goals.
At Next ‘26, James Sun, Member of Technical Staff at Thinking Machines Lab, spoke at our session, Cloud Storage Rapid: Turbocharged object storage for AI & Analytics, where he presented about the needs of the data-hungry AI/ML workloads that Thinking Machines Lab runs for high-performance storage at scale.
Thinking Machines runs diverse workflows: data processing in Dataflow, Kafka, and Spark, multi-model training, and serving Tinker — a flexible API for fine-tuning open source models. Thinking Machines’ workloads run on Google Cloud Storage, Sun explained. Running these data-intensive AI/ML workloads at such a large scale introduces significant infrastructure challenges.
The first is managing a hub and spoke data architecture, where data processing hubs are located in one primary region while training GPUs are spread across multiple regions. Historically, this has made manual data movement and lifecycle management a major operational pain point. Furthermore, Thinking Machines Lab’s workloads such as data prep and pretraining workflows, which rely on massive-scale Spark workloads to prepare their multi-modal datasets, often spike from cold to hot instantly. Previously, these surges led to disruptive 429 errors, which stalled data processing and loading, and interrupted critical training cycles.
To minimize these bottlenecks, Thinking Machines Lab integrated Rapid Cache across their AI/ML pipeline, to positive results.
“Rapid Cache has become a core foundation of our AI/ML data infrastructure, supporting our critical workflows, from data prep and pretraining to training and model loading. By acting as a crucial bandwidth shield and booster, it enables us to scale our data-intensive workloads across our entire fleet without compromise, providing us with the on-demand high bandwidth and consistent stability that we need to innovate at speed.” – James Sun, Member of Technical Staff, Thinking Machines Lab
In short, Cloud Storage and Rapid Cache provides Thinking Machines Lab with:
-
Easy, instant, scalable, on demand bandwidth: The team now achieves stable read throughput peaks of over 1.8TB/s.
-
Enhanced stability: Rapid Cache has greatly reduced tail-end latencies and 429 errors, providing the consistent performance needed for multi-modal training.
-
Fleet-wide scalability: Combined with multi-region buckets, they can now scale data-intensive workloads across their entire fleet, meeting the demands of a rapidly growing compute scale without the hassle of manual data movement while benefiting from zonally colocated storage for high performance.
- Operational efficiency: The use of Hierarchical Namespace (HNS) has optimized their massive Spark workloads for data preparation, by supporting fast directory renames, along with providing the ability to ramp QPS more quickly as they scale out clusters. Rapid Cache’s “ingest on write” capability helps ensure immediate cache hits for checkpoint restores.

Choose your rocket ship
Whether you are running data preparation, massive-scale training, or low-latency inference, Cloud Storage Rapid delivers high performance together with the reliability and scalability that Cloud Storage is known for.
-
Rapid Bucket delivers the highest Cloud Storage throughput and queries per second as well as the lowest latency for read/write use cases, such as analytics, AI training, checkpointing, and model serving. This helps to reduce storage bottlenecks and increase compute utilization.
-
Rapid Cache provides higher read bandwidth and tail latency stabilization in existing buckets, without code changes. Key use cases include AI training, checkpoint restores, and serving, as well as accelerator optionality via multi-region buckets.
Get started with the Cloud Storage Rapid family today!